Algorithm Visualization Introduction
For Beginners or Quick Learners
I have prepared visualization code for each problem. In the article and comments, I will tell you how to use the visual panel to see the algorithm running.
So for beginners or readers who want to quickly master algorithms, just read the first part "Basic Usage" of this article.
For Advanced Readers or Algorithm Fans
Some readers may want to change my preset code or test their own ideas visually. For this, you can read the second part of this article to learn more about the panel’s special features.
The visual panel now only supports JavaScript. If you are not familiar with JavaScript, I wrote a Simple JavaScript Tutorial for Panel that can help you get started in 5 minutes.
Panel editor web page:
https://labuladong.online/algo-visualize/
Quick guide for classic algorithm visual panels:
https://labuladong.online/zh/visualization/
There is also an "Edit" button in each visual panel on the site and in the related plugins. You can click it to change and run your own code to see the visualization.
Basic Usage
Left side is the code area. The current running line will be highlighted. Click any code line to run straight to that line. If you put your mouse over a code line for 0.5s, you can quickly jump to the previous or next execution.
Most Useful Trick
The "click code to jump to a line" feature is the most used. This is just like the "run to cursor" feature when you are debugging in your IDE.
Usually, we don’t step through each line from the start. We click on a line we care about, then step forward one by one to watch how the algorithm works.
Top area has control buttons and sliders. You can carefully control the step by step process. The Edit button lets you change my preset code.
Right side is the visualization area. It shows variables, data structures, stack info, recursion trees and more. Mouse over any structure to see more details.
Left bottom is the Log Console. If your code uses console.log, the output is shown here.
Right bottom has floating buttons for copying code, copying the link, refreshing the panel, full-screen mode, and showing/hiding the Log Console. If the panel looks too small, you can click the full-screen button to see it better.
With this, you’re ready to use the visualization panel! Let's try and play with these features.
Open the following visualization about binary tree level order traversal. Click the console.log line to see how the cur pointer visits each node from left to right, level by level. You will also see the node’s level being printed:
Binary Tree Level Order Traversal
Open the following panel to see spiral traversal of a 2D array. Click the while (res.length < m * n) line a few times to see how the algorithm visits elements layer-by-layer in a spiral:
Spiral Traversal of a 2D Array
Beginners can stop here. The following explains more special features of the visual panel, for readers who need them.
Visualization of Data Structures
The panel can visualize common data structures such as arrays, linked lists, binary trees, hash tables, and hash sets. Below is a detailed introduction on how to create these data structures.
Standard Library Data Structures
For JavaScript's built-in data structures like arrays and hash tables, simply initialize and operate them as usual, for example:
Algorithm Visualization
Singly Linked List
Let's first talk about singly linked lists. Each node in a singly linked list has val and next attributes, which are exactly the same as the definition used on LeetCode.
API Documentation
// Singly linked list node
abstract class ListNode {
val: any
next: ListNode | null
constructor(val: any, next: ListNode | null = null) {
this.val = val
this.next = next
}
}
abstract class LinkedList {
// Create a linked list and return the head node
static createHead(elems: any[]): ListNode {
}
// Create a linked list with a cycle and return the head node
static createCyclicHead(elems: any[], index: number): ListNode {
}
}Algorithm Visualization
Doubly Linked List
Each node in a doubly linked list has val, prev, and next properties, with a constructor identical to that used in LeetCode.
API Documentation
// Double linked list node
abstract class DListNode {
next: DListNode | null = null
prev: DListNode | null = null
val: any
constructor(val: any = 0, prev: DListNode = null, next: DListNode = null) {
this.val = val
this.prev = prev
this.next = next
}
}
// Double linked list
abstract class DLinkedList {
// Create a double linked list and return the head node
static createHead(elems: any[]): DListNode {
}
}Algorithm Visualization
Hash Table Based on Chaining
The JavaScript standard library provides a Map for storing key-value pairs. The hash table provided here is mainly for educational purposes, to accompany Principles and Implementation of Hash Tables.
The ChainingHashMap.create method can create a simplified hash table based on chaining, which only supports storing integer key-value pairs and does not support resizing. For specific implementation details, refer to Hash Table Implementation Using Chaining.
API Documentation
// A simplified version of chaining hash map
abstract class ChainingHashMap {
// Create a chaining hash map with capacity
static create(capacity: number): ChainingHashMap {
}
// Add or Update key-value pair
abstract put(key: number, value: number): void;
// Get the value of a key, return -1 if not found
abstract get(key: number): number;
// Remove a key-value pair
abstract remove(key: number): void;
// Get the internal array
abstract getTable(): Array<ListNode | null>;
// Get the head node of the linked list at a given
abstract getTableIndex(index: number): ListNode | null;
}Algorithm Visualization
Hash Table Based on Linear Probing
Similar to the chaining method, the hash table based on linear probing is also designed for teaching purposes to complement the article Principles and Implementation of Hash Tables.
The LinearProbingHashMap.create method can create a simplified hash table based on linear probing. It only supports storing integer key-value pairs and does not support resizing. For detailed implementation, you can refer to Implementing Hash Tables with Linear Probing.
API Documentation
// A simplified version of linear probing hash map
abstract class LinearProbingHashMap {
// Create a linear probing hash map with capacity
static create(capacity: number): LinearProbingHashMap {
}
// Add or Update key-value pair
abstract put(key: number, value: number): void;
// Get the value of a key, return -1 if not found
abstract get(key: number): number;
// Remove a key-value pair
abstract remove(key: number): void;
// Get the internal array
abstract getTable(): Array<string | null>;
}Algorithm Visualization
Binary Tree
Each node in a binary tree has the properties val, left, right, consistent with the constructor in LeetCode.
You can quickly create a binary tree using the BTree.create method. Note that we use a list to represent the binary tree, in the same way as the representation of binary trees in LeetCode problems.
API Documentation
// Binary Tree Node
abstract class TreeNode {
val: any
left: TreeNode | null
right: TreeNode | null
constructor(val: any, left: TreeNode | null = null, right: TreeNode | null = null) {
this.val = val
this.left = left
this.right = right
}
}
abstract class BTree {
// Create a binary tree root node from an array in the format of LeetCode
static createRoot(elems: any[]): TreeNode {
}
// Create a BST from a list of elements, return the root node
static createBSTRoot(elems: number[]): TreeNode {
}
}Algorithm Visualization
N-ary Tree
Each node in an N-ary tree has val and children attributes, with the constructor being identical to the one used in LeetCode.
API Documentation
// N-ary tree node
abstract class NTreeNode {
val: any
children: NTreeNode[]
}
abstract class NTree {
// Create an N-ary tree from an array
// The input format is similar to this LeetCode problem:
// https://leetcode.com/problems/n-ary-tree-level-order-traversal/
static create(items: any[]) {
}
}Algorithm Visualization
Standard Binary Search Tree
You can use BSTMap.create to create a standard binary search tree for storing key-value pairs. For the underlying principles, refer to Implementing TreeMap/TreeSet.
If you do not need to store key-value pairs, you can use BTree.createBSTRoot mentioned above to create a binary search tree based on standard binary tree nodes.
API Documentation
type compareFn = (a: any, b: any) => number
const defaultCompare = (a: any, b: any) => {
if (a === b) return 0
return a < b ? -1 : 1
}
abstract class BSTNode {
abstract key: any
abstract value: any
abstract left: null | BSTNode
abstract right: null | BSTNode
}
abstract class BSTMap {
static create(elems: any[] = [], compare: compareFn = defaultCompare): BSTMap {
}
abstract get(key: any): any
abstract containsKey(key: any): boolean
abstract put(key: any, value: any): void
abstract remove(key: any): void
abstract getMinKey(): any | null
abstract getMaxKey(): any | null
abstract keys(): any[]
abstract _getRoot(): BSTNode | null
}Red-Black Binary Search Tree
You can create a red-black binary search tree to store key-value pairs using the RBTreeMap class. For usage examples, refer to Red-Black Tree Basics.
API Documentation
type compareFn = (a: any, b: any) => number
const defaultCompare = (a: any, b: any) => {
if (a === b) return 0
return a < b ? -1 : 1
}
// Red-Black Tree Node
abstract class RBTreeNode {
// Node color
static RED: string = '#b10000'
static BLACK: string = '#464546'
abstract key: any
abstract value: any
abstract color: string
abstract left: null | RBTreeNode
abstract right: null | RBTreeNode
static isRed(node: RBTreeNode): boolean {
if (!node) return false
return node.color === RBTreeNode.RED
}
}
abstract class RBTreeMap {
static create(elems: any[][] = [], compare: compareFn = defaultCompare): RBTreeMap {
}
abstract put(key: any, value: any): void
abstract get(key: any): any
abstract containsKey(key: any): boolean
abstract getMinKey(): any | null
abstract getMaxKey(): any | null
abstract deleteMinKey(): void
abstract deleteMaxKey(): void
abstract delete(key: any): void
abstract keys(): any[]
abstract _getRoot(): RBTreeNode | null
// Some key methods of Red-Black Tree
static makeNode(key: any, value: any, color: string): RBTreeNode {
}
static makeRedNode(key: any, value: any): RBTreeNode {
}
static makeBlackNode(key: any, value: any): RBTreeNode {
}
// Left rotation operation
static rotateLeft(node: RBTreeNode): RBTreeNode {
}
static moveRedLeft(node: RBTreeNode): RBTreeNode {
}
// Right rotation operation
static rotateRight(node: RBTreeNode): RBTreeNode {
}
static moveRedRight(node: RBTreeNode): RBTreeNode {
}
// Color flip
static flipColors(node: RBTreeNode): void {
}
// Balance operation
static balance(node: RBTreeNode): RBTreeNode {
}
}Binary Heap (Priority Queue)
In Binary Heap Basics and Implementation, I explained the fundamental concepts of binary heaps, the code implementation of priority queues, and the two core operations: swimming (swim) and sinking (sink), using a visual panel. Additionally, some methods of binary heaps are also used in Heap Sort Algorithm Details to perform sorting.
API Documentation
type compareFn = (a: any, b: any) => number
const defaultCompare: compareFn = (a, b) => {
if (a < b) return -1;
if (a > b) return 1;
return 0;
};
// Binary heap node
abstract class HeapNode {
abstract val: any;
abstract left: HeapNode;
abstract right: HeapNode;
}
abstract class Heap {
// Create a heap, you can pass in initial elements or a comparison function
static create(items: any[] = [], fn: compareFn = defaultCompare): Heap {
}
// Create a max heap, you can pass in initial elements
static createMax(items?: any[]): Heap {
}
// Create a min heap, you can pass in initial elements
static createMin(items?: any[]): Heap {
}
// Create a binary heap node
static makeNode(value: any): HeapNode {
}
// Add an element to the top of the heap
abstract push(value: any): void;
// Pop the top element of the heap
abstract pop(): any;
// View the top element of the heap
abstract peek(): any;
// Get the number of elements in the heap
abstract size(): number;
// Display the underlying array
abstract showArray(varName?: string): any[];
// Return the root node of the heap
// Mainly used to explain the principle of binary
abstract _getRoot(): HeapNode | null;
// Convert an array to a complete binary tree, but will not apply the properties of heap
// Mainly used to explain heap sort
static init(items: any[], fn: compareFn = defaultCompare) {
}
// Make the node swim up and maintain the properties of the binary heap
// Mainly used to explain heap sort
static sink(heap: Heap, topIndex: number, size: number, compare: compareFn) {
}
// Make the node sink and maintain the properties of the binary heap
// Mainly used to explain heap sort
static swim(heap: Heap, index: number, compare: compareFn) {
}
}The visualization panel by default displays a binary heap in the logical structure of a binary tree. By calling the showArray method, you can simultaneously display the underlying array structure of the binary heap. Below are some examples of usage:
Algorithm Visualization
Segment Tree
The SegmentTree class allows for the creation of segment trees and supports methods such as query and update. The underlying principles can be found in Introduction to Segment Trees.
Currently, built-in segment trees for sum, maximum, and minimum values are available. You can directly use the SegmentTree.create method to create a custom segment tree.
API Documentation
type mergeFn = (a: any, b: any) => any
const sumMerger = (a: any, b: any) => a + b
const maxMerger = (a: any, b: any) => Math.max(a, b)
const minMerger = (a: any, b: any) => Math.min(a, b)
// Segment tree node
abstract class SegmentNode {
abstract val: any
abstract l: number
abstract r: number
abstract left: SegmentNode | null
abstract right: SegmentNode | null
}
// Segment tree
abstract class SegmentTree {
// Create a custom segment tree
// merger is a function that defines the merge logic of the segment tree
// mergerName is the name of the merge rule, to display on visualization panel
static create(items: any[], merger: mergeFn = sumMerger, mergerName: string = 'sum'): SegmentTree {
}
// Create a sum segment tree, supports range sum query and single update
static createSum(items: any[]): SegmentTree {
return SegmentTree.create(items, sumMerger, 'sum')
}
// Create a min segment tree, supports range min query and single update
static createMin(items: any[]): SegmentTree {
return SegmentTree.create(items, minMerger, 'min')
}
// Create a max segment tree, supports range max query and single update
static createMax(items: any[]): SegmentTree {
return SegmentTree.create(items, maxMerger, 'max')
}
// Update the value at index to value
abstract update(index: number, value: any): void
// Query the value of the closed interval [left, right]
abstract query(left: number, right: number): any
// Show the underlying array
abstract showArray(varName: string): any[]
// Get the root node of the segment tree
abstract _getRoot(): SegmentNode | null
}The visualization panel below creates a segment tree for summation, displaying the logical structure of the segment tree, the underlying array, and basic operations such as query and update:
Algorithm Visualization
Graph Structures
In the article Fundamentals and General Implementations of Graph Structures, I discussed how the logical structure of graphs is similar to multi-way trees and can be represented using Vertex and Edge classes for vertices and edges. However, in practice, when implementing graph structures in code, we typically use adjacency lists or adjacency matrices.
The visualization panel also implements a Graph class to create graph structures, supporting weighted/unweighted and directed/undirected graphs. For educational purposes, the Graph class in the visualization panel maintains three implementation methods: adjacency lists, adjacency matrices, and the Vertex, Edge classes.
Here is an example using DFS to find all paths from node 0 to node 4 in a graph. You can click the line if (s === n - 1) multiple times to observe the graph traversal process:
Algorithm Visualization
API Documentation
// Adjacency list structure type
type AdjacencyList = {
// key is the vertex id
// value is an array, storing information of neighbor nodes
// If it is an unweighted graph, the array element is a number, representing
// If it is a weighted graph, the array element is an array, the first
// element is the node id, the second element is the weight of the edge
[key: number]: (number | [number, number])[];
};
abstract class Graph {
// Create a directed graph from multiple edges
// Each element in edges is an array representing a directed edge
// The first element is the start vertex id, the second element is the end vertex id
// If there is a third element, it represents the weight of the edge
// If there is no third element, the graph is unweighted
static createDirectedGraphFromEdges(edges: any[][]): Graph {
}
// Create an undirected graph from multiple edges
// The input format is similar to
// createDirectedGraphFromEdges, except that the edges are undirected
static createUndirectedGraphFromEdges(items: any[][]): Graph {
}
// Create a directed graph from adjacency list
// adjList is an array, each element is an array representing the neighbors of a vertex
// If the neighbor is a number, it represents an unweighted edge
// Example:
// Graph.createDirectedGraphFromAdjList([
// [1], [2], [0]
// ])
// A directed graph with three vertices, three edges are 0 -> 1, 1 -> 2, 2 -> 0
// If the neighbor is an array, the first element is the end
// vertex id, the second element is the weight of the edge
// Example:
// Graph.createDirectedGraphFromAdjList([
// [[1, 9]],
// [[2, 8]],
// [[0, 5]]
// ])
// A directed graph with three vertices, three edges are 0 ->
// 1, 1 -> 2, 2 -> 0, with weights 9, 8, 5 respectively
static createDirectedGraphFromAdjList(adjList: (number | [number, number])[][]): Graph {
}
// Create an undirected graph from adjacency list
// The input format is similar to
// createDirectedGraphFromAdjList, except that the edges are undirected
static createUndirectedGraphFromAdjList(adjList: (number | [number, number])[][]): Graph {
}
// Get the neighbor node id of the node
abstract neighbors(id: number): number[]
// Get the weight of the edge from->to
// If it is an unweighted graph, the default return is 1
abstract weight(from: number, to: number): number
// Get the number of vertices
abstract length(): number
// Return the adjacency list structure
abstract getAdjList(): AdjacencyList
// Return the adjacency matrix structure
abstract getAdjMatrix(): number[][]
// Get the vertex object by id, only used for visualization coloring
abstract _v(id: number): Vertex
// Get the from->to Edge object, only used for visualization coloring
abstract _e(from: number, to: number): Edge
}
// Vertex object
abstract class Vertex {
id: any
}
// Edge object
abstract class Edge {
from: Vertex
to: Vertex
weight: number
}Union-Find
The UF class can create a union-find structure, which is used to solve dynamic connectivity problems in graph structures. The underlying principles can be found in Core Principles of Union-Find.
Since the union-find structure can be optimized in various ways, such as path compression and weighted union, the UF class offers multiple initialization methods:
UF.createNative(n: number): Creates an unoptimized union-find structure withnnodes.UF.createWeighted(n: number): Creates a union-find structure optimized with a weight array, containingnnodes.UF.createPathCompression(n: number): Creates a union-find structure optimized with path compression, containingnnodes.
The UF object mainly provides the following three methods to solve dynamic connectivity problems:
union(p: number, q: number): Merges the connected components containing nodespandq.connected(p: number, q: number): Determines if nodespandqare in the same connected component.count(): Returns the number of connected components in the current union-find structure.
The logical structure of a union-find is a forest (several multi-way trees). For easier visualization, a virtual node is created in this forest. The virtual node is transparent, with the root of each multi-way tree displayed in red and regular nodes in green. This allows the forest structure to be displayed as a multi-way tree while making it easy to see the root of each connected component.
The union-find is implemented using an array to represent the forest. By calling the showArray method, the visualization panel can simultaneously display this underlying array.
Below is an example of a union-find optimized with a weight array:
API Documentation
abstract class UF {
// Create a naive union-find with size n
static createNaive(n: number): UF {
}
// Create a weighted union-find with size n
static createWeighted(n: number): UF {
}
// Create a path compression union-find with size n
static createPathCompression(n: number): UF {
}
// Create a union-find with size n, default to path compression
static create(n: number): UF {
return UF.createPathCompression(n)
}
// Find the root of p
find(p: number): number {
}
// Merge the connected components of p and q
union(p: number, q: number): void {
}
// Check if p and q are in the same connected component
connected(p: number, q: number): boolean {
}
// Return the number of connected components
count(): number {
}
// Show the parent array of the union-find
showArray(varName: string): void {
}
}Algorithm Visualization
Trie Tree/Prefix Tree/Dictionary Tree
Trie.create() allows you to create a Trie tree, where blue nodes are regular Trie nodes and purple nodes are nodes that contain words. Hovering over a node will display the word stored in that node.
API Documentation
// Trie Node
abstract class TrieNode {
abstract char: string
abstract isWord: boolean
abstract children: TrieNode[]
}
// Trie API
abstract class Trie {
// Create a trie, words will be added to the trie
static create(words?: string[]): Trie {
}
// Add a string to the trie
add(word: string) {
}
// Remove a string from the trie
remove(word: string) {
}
// Return the shortest prefix of word
shortestPrefixOf(word: string) {
}
// Return the longest prefix of word
longestPrefixOf(word: string) {
}
// Check if there is a string with prefix
hasKeyWithPrefix(prefix: string) {
}
// Return all strings with prefix
keysWithPrefix(prefix: string) {
}
// Return all strings that match the pattern
keysWithPattern(pattern: string) {
}
// Check if the word exists in the trie
containsKey(word: string) {
}
// Return the number of strings in the trie
size() {
}
}Algorithm Visualization
Enhanced console.log
Previously, I shared a technique for debugging recursive algorithms using only standard output during exams, which involves using additional indentation to distinguish recursion depth.
To make it easier for everyone to observe the output of complex algorithms more intuitively, I enhanced the console._log function in the visualization panel.
The specific enhancements are as follows:
If you use the
console._logfunction in the visualization panel, the output will be printed in the Log Console at the bottom left, with automatic indentation added based on recursion depth.Clicking on the output in the console will display a dashed line that aligns all outputs with the same indentation, helping you understand which outputs belong to the same recursion depth.
Indentation by Recursion Level
The code outputs when starting and ending a recursion. You can see that the console in the bottom left displays the following output, with outputs from the same recursion depth having the same indentation for easy distinction:
enter traverse(1)
enter traverse(2)
enter traverse(3)
enter traverse(4)
leave traverse(4)
leave traverse(3)
leave traverse(2)
leave traverse(1)You can click on the first character e or l of each line of output in the console to see a dashed line that aligns all outputs with the same indentation, making it easier to see the correspondence between enter and leave.
Sorting Algorithm Visualization
The @visualize shape nums rect annotation can convert an array into a histogram-like form based on element size, which helps in intuitively understanding the size relationship of array elements and observing the execution process of sorting algorithms. Using @visualize shape nums cycle can revert the array elements to the default circular display.
Here's an example with Insertion Sort:
Insertion Sort
Variable Binding as Array Index
By default, when a variable name is used as an index to access an array, the variable automatically binds to the array, and a cursor will appear showing the element the variable points to. However, sometimes a variable might not directly access the array elements, but we still want it to appear on the array.
For instance, in the insertion sort visualization above, the sortedIndex variable never accesses the array like nums[sortedIndex] in the code, but we want the sortedIndex variable to be displayed in the visual panel on the right because it marks the boundary between sorted and unsorted elements.
In such cases, we can use the @visualize bind nums[sortedIndex] annotation to bind the sortedIndex variable to the nums array, displaying a cursor showing the position of sortedIndex on the right-side array.
To unbind, you can use the @visualize unbind nums[sortedIndex] annotation.
Color System
You can use the @visualize color annotation to set the color of nodes/elements. The color is a hexadecimal color code starting with #, such as #8ec7dd for light blue.
The color code can include ?, indicating a random hexadecimal number to generate random colors, like #8e??dd.
In the insertion sort visualization above, I used @visualize color nums[sortedIndex] #8ec7dd to set the color of the sortedIndex variable. The array element pointed by the sortedIndex will turn light blue, and once the sortedIndex moves to a new index, the old index's element will revert to the default color.
If you want to color a specific index without moving with the variable, use * to declare a fixed element color, which doesn't move with the variable.
For instance, @visualize color *nums[0] #8ec7dd or @visualize color *nums[sortedIndex] #8ec7dd, when sortedIndex = 2, nums[2] will become light blue, and regardless of the changes in sortedIndex, nums[2] will remain light blue.
The same applies to node objects; you can color variables, such as @visualize color root #8ec7dd, or color specific nodes, like @visualize color *root.left #8ec7dd.
To unset a color, use #unset as the color code, like @visualize color *root.left #unset, to revert to the default color.
After setting colors with @visualize color, the color code will appear as a color picker, and you can click it to modify the color.
Variable Hiding and Scope Elevation
Using @visualize global, you can elevate a variable's scope to global, allowing closure variables to remain visible in the right-side visualization panel.
Using @visualize hide, you can hide variables to prevent the right-side visualization panel from becoming cluttered with irrelevant data structures.
Let's illustrate these annotations with an example. Suppose I want to implement a simple Stack class with push, pop, peek methods. I can write it using JavaScript function closures:
Algorithm Visualization
But in the last step, you will see the stack variable always appears as an Object in the right-side visualization panel without practical meaning and occupies a lot of space.
We are more concerned with the items variable because we can observe the array's element changes to understand how the push, pop methods work.
However, since items is declared inside the Stack function, it is not in the current scope when executing outside the function body, so the right-side panel does not visualize it.
In such a case, we can use the @visualize global annotation to elevate the items variable to the global scope, and use the @visualize hide annotation to hide the stack variable in the right-side panel.
This achieves the desired effect. Click the stack.push(1); line of code and proceed, and you will see the stack variable no longer appears, while the items array's update process displays on the right:
Algorithm Visualization
Visualization of Backtracking/DFS Recursive Process
Recursive algorithms can be challenging for many readers. I previously wrote an article, Understanding All Recursive Algorithms from a Tree Perspective, which abstractly outlines the fundamental thinking model and writing techniques for recursive algorithms.
In simple terms: Consider the recursive function as a pointer on a recursive tree. Backtracking algorithms traverse a multi-branch tree and collect the values of the leaf nodes; dynamic programming involves decomposing a problem and using the solutions of subproblems to derive the solution of the original problem.
Now, I have integrated the thinking model discussed in the article into an algorithm visualization panel, which will surely help you understand the execution process of recursive algorithms more intuitively.
For recursive algorithms, the annotations @visualize status, @visualize choose, and @visualize unchoose can be very helpful. Below, I will introduce them one by one.
Example of @visualize status
In short, the @visualize status annotation can be placed above a recursive function that needs visualization, to control the values of nodes in the recursion tree.
Let's take a simple example. When explaining the Core Framework of Dynamic Programming Algorithms, I illustrated the recursion tree for the Fibonacci problem, where larger problems at the top are gradually decomposed:
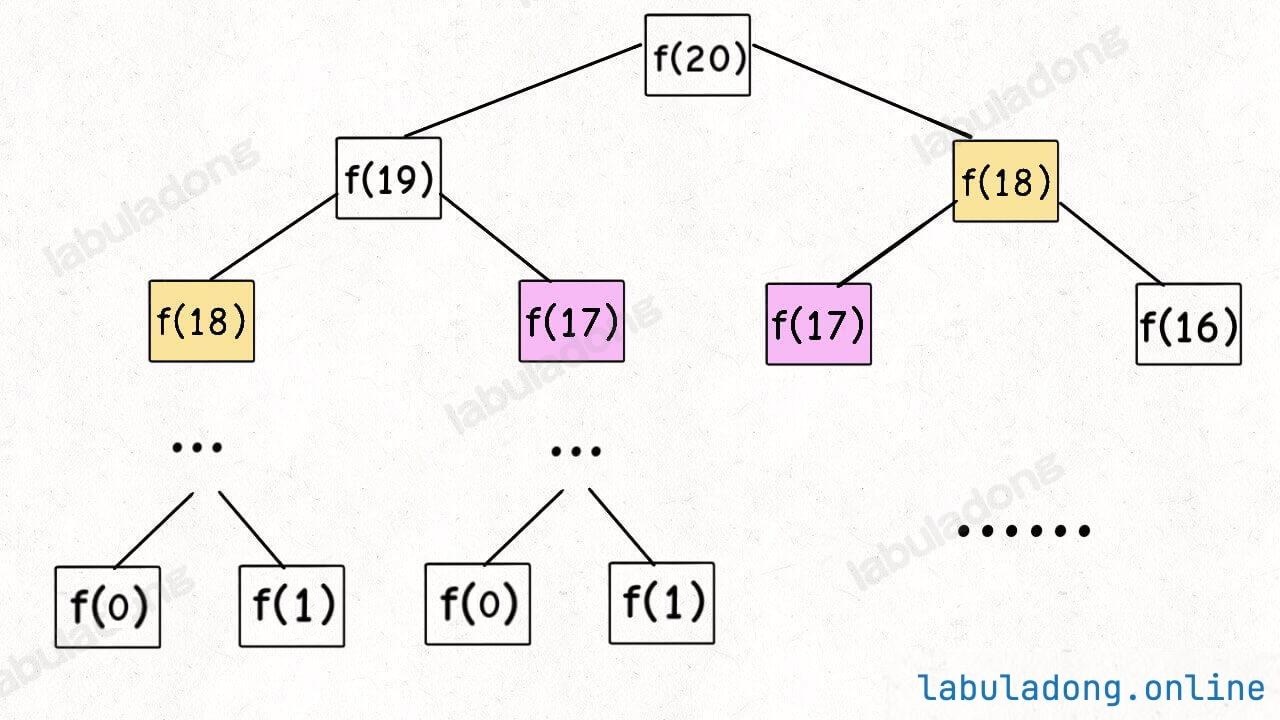
How do we describe the process of an algorithm running? The recursive function fib acts like a pointer on the recursion tree, repeatedly decomposing the original problem into subproblems. When the problem is broken down to a base case (leaf node), it starts returning the answers of subproblems layer by layer, deriving the answer to the original problem.
With the @visualize status annotation, this process can be seen clearly. The panel below shows the recursion tree of the Fibonacci algorithm, attempting to compute the value of fib(3):
Example of Dynamic Programming Recursion Tree
The @visualize status annotation placed above the fib function means:
It enables the recursion tree visualization for this
fibfunction, with each recursive call visualized as a node on the recursion tree. The value ofnin the function parameters is displayed as the state on the node.The
fibfunction is seen as a pointer traversing this recursion tree, with branches along the stack path highlighted.If the function has a return value, once the function ends and a return value for a node is calculated, hovering the mouse over this node will display the return value.
Practical Exercise
Please enter 27 in the step box and press enter to jump to step 27. Hover the mouse over node (2) to see fib(2) = 1, indicating that the value of fib(2) has been calculated.
Nodes on the recursion path, such as (5),(4),(3), have not yet had their values calculated, and hovering over them will not display a return value.
Practical Exercise
Try clicking the forward and backward buttons on the visualization panel to run the algorithm a few steps further, and understand the growth process of the recursion tree in dynamic programming.
Practical Exercise
When the entire recursion tree is fully traversed, the original problem fib(5) will be computed, and all nodes on the recursion tree will display return values.
Try dragging the progress bar to the end to see what the recursion tree looks like, and hover over each node to see what is displayed.
The previously shown Fibonacci solution code did not include memoization, resulting in an exponential time complexity. Now, let's experience how adding memoization affects the growth of the recursion tree.
Practical Exercise
👇 Please drag the progress bar to the end of the algorithm to see what the recursion tree looks like.
Fibonacci Algorithm Without Memoization Optimization
Practical Exercise
👇 Here is a version with memoization optimization. Drag the progress bar to the end of the algorithm to see what the recursion tree looks like and compare it with the one without memoization optimization.
Fibonacci Algorithm with Memoization
By visualizing the entire tree this way, you can intuitively understand how dynamic programming uses memoization to eliminate overlapping subproblems.
@visualize choose/unchoose Example
In short, the @visualize choose/unchoose annotations are placed before and after the recursive function calls, respectively, to control the values on the branches of the recursion tree.
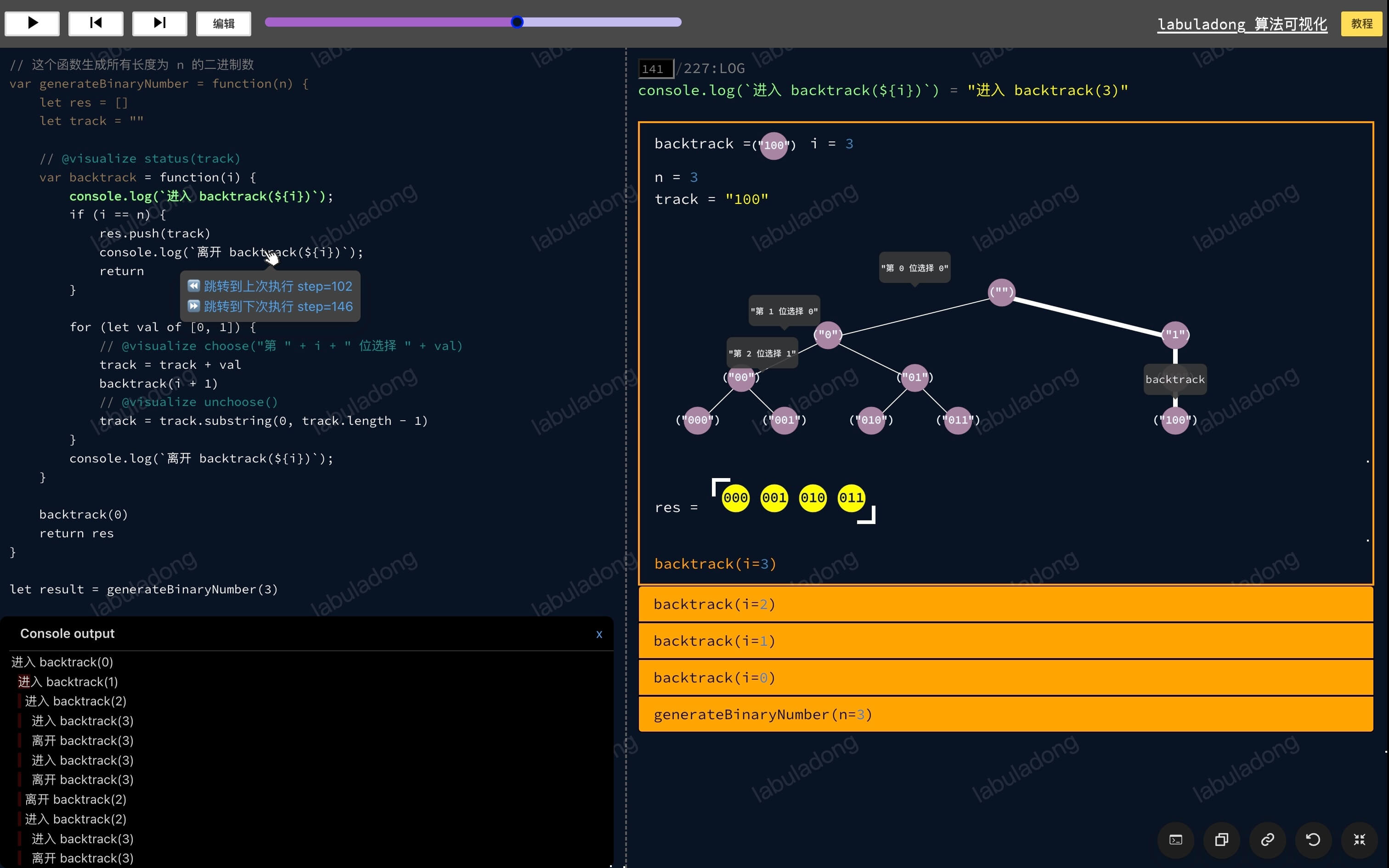
Let me illustrate with a simple backtracking problem. For instance, you need to write a generateBinaryNumber function that generates binary numbers of length n. For example, when n = 3, the function should generate 000, 001, 010, 011, 100, 101, 110, 111, which are the 8 binary numbers.
The solution code for this problem isn't complex. I'll demonstrate how to use the @visualize choose/unchoose annotations to visualize the backtracking process:
Algorithm Visualization
You can hover your mouse over any node in the recursion tree to display all the information on the path from the root node to that node.
Understanding the recursion algorithm code in conjunction with this recursion tree makes it quite intuitive, doesn't it?
BFS Process Visualization
As mentioned in Binary Tree Thinking (Overview), the BFS algorithm is an extension of the level-order traversal of a binary tree.
Since recursion trees can be visualized, the BFS process can also be visualized. You can use @visualize bfs to enable the automatic visualization of the BFS algorithm, generating a brute-force tree. The values on the nodes represent the values of elements in the queue, and with @visualize choose/unchoose annotations, you can control the values on the branches.
Below, I will demonstrate the visualization of the BFS process with a simple example: