Cycle Detection and Topological Sort Algorithm
This article will resolve
| LeetCode | Difficulty |
|---|---|
| 207. Course Schedule | 🟠 |
| 210. Course Schedule II | 🟠 |
Prerequisite Knowledge
Before reading this article, you need to first learn:
Summary in One Sentence
Before performing topological sorting, ensure there are no cycles in the graph.
The "reverse post-order traversal" of a graph is the result of topological sorting.
Graph as a data structure has some special algorithms, such as bipartite graph detection, cycle detection, topological sorting, the classic minimum spanning tree, and single-source shortest path problems. More complex ones include problems like network flow.
However, at the moment, there's no need to learn network flow problems unless you're preparing for competitions and have the time; algorithms like Minimum Spanning Tree and Shortest Path Problem, although not frequently encountered in problem-solving, are classic algorithms worth mastering if you have extra time; algorithms like Bipartite Graph Detection and topological sorting are essentially graph traversals, which are basic algorithms that should be mastered proficiently.
In this article, we will discuss two graph theory algorithms through specific algorithm problems: cycle detection in directed graphs and topological sorting algorithms.
Both of these algorithms can be solved using either DFS or BFS approaches. BFS solutions tend to be more concise in terms of code implementation, but DFS solutions help you further understand the essence of recursive traversal of data structures. Therefore, in this article, I will first explain the DFS traversal approach, followed by the BFS traversal approach.
Cycle Detection Algorithm (DFS Version)
Let's first look at LeetCode Problem 207: "Course Schedule":
207. Course Schedule | LeetCode | 🟠
There are a total of numCourses courses you have to take, labeled from 0 to numCourses - 1. You are given an array prerequisites where prerequisites[i] = [ai, bi] indicates that you must take course bi first if you want to take course ai.
- For example, the pair
[0, 1], indicates that to take course0you have to first take course1.
Return true if you can finish all courses. Otherwise, return false.
Example 1:
Input: numCourses = 2, prerequisites = [[1,0]] Output: true Explanation: There are a total of 2 courses to take. To take course 1 you should have finished course 0. So it is possible.
Example 2:
Input: numCourses = 2, prerequisites = [[1,0],[0,1]] Output: false Explanation: There are a total of 2 courses to take. To take course 1 you should have finished course 0, and to take course 0 you should also have finished course 1. So it is impossible.
Constraints:
1 <= numCourses <= 20000 <= prerequisites.length <= 5000prerequisites[i].length == 20 <= ai, bi < numCourses- All the pairs prerequisites[i] are unique.
// The function signature is as follows
boolean canFinish(int numCourses, int[][] prerequisites);// The function signature is as follows
bool canFinish(int numCourses, vector<vector<int>>& prerequisites);# The function signature is as follows
def canFinish(numCourses: int, prerequisites: List[List[int]]) -> bool:// The function signature is as follows
func canFinish(numCourses int, prerequisites [][]int) bool {}// the function signature is as follows
var canFinish = function(numCourses, prerequisites);The problem should be easy to understand: when is it impossible to complete all courses? When there is a circular dependency.
In fact, this scenario is quite common in real life. For example, when we write code to import packages, a well-designed directory structure is necessary to avoid circular dependencies. Otherwise, the compiler will throw an error, as it uses a similar algorithm to determine whether your code can be successfully compiled.
When you encounter a dependency issue, the first thought should be to transform the problem into a "directed graph" data structure. If there is a cycle in the graph, it indicates a circular dependency.
Specifically, we can first consider courses as nodes in a "directed graph," with node numbers ranging from 0, 1, ..., numCourses-1. The dependencies between courses can be viewed as directed edges between nodes.
For instance, if you must complete course 1 before taking course 3, there will be a directed edge from node 1 to node 3.
Therefore, we can generate a graph similar to this based on the prerequisites array provided in the problem input:
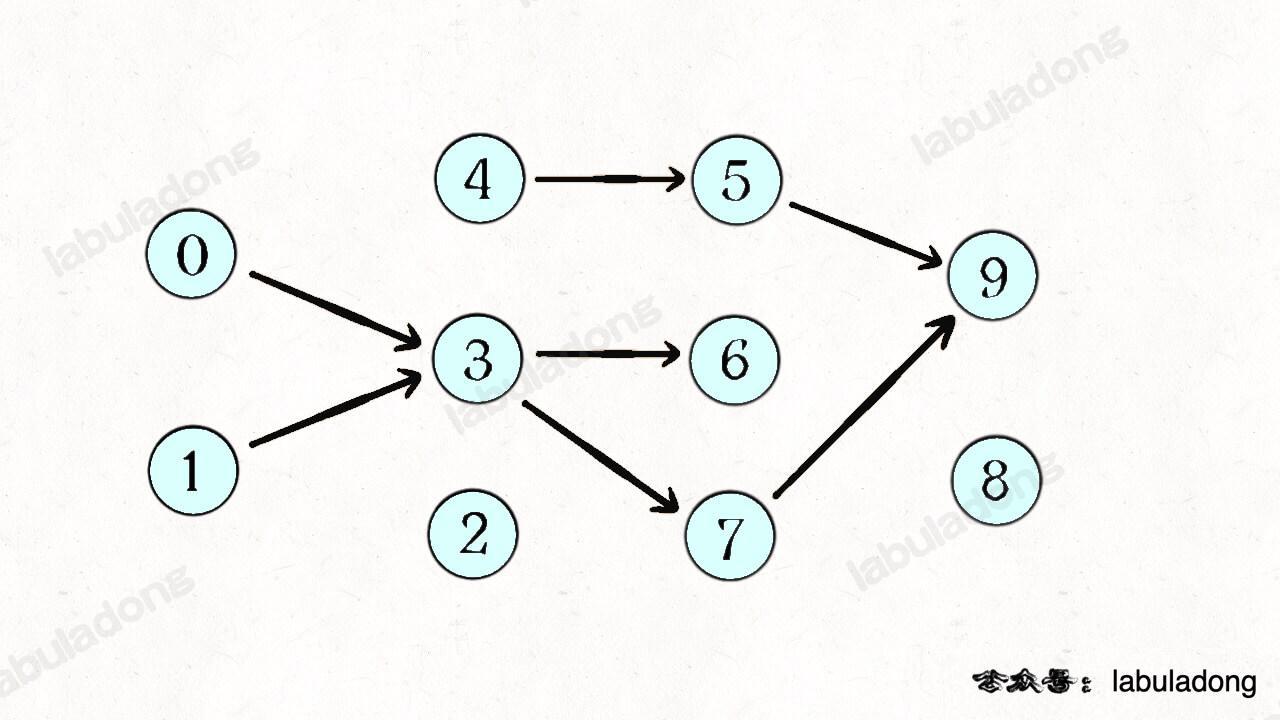
If a cycle is found in the directed graph, it indicates a circular dependency between courses, making it impossible to complete all of them. Conversely, if there is no cycle, it is possible to complete all courses.
To solve this problem, we need to first transform the problem input into a directed graph and then check for cycles in the graph.
How do we convert it into a graph? In our previous discussion on Graph Structure Storage, we covered two ways to store a graph: an adjacency matrix and an adjacency list.
Here, I will use the adjacency list to store the graph and start by writing a function to build the graph:
List<Integer>[] buildGraph(int numCourses, int[][] prerequisites) {
// There are numCourses nodes in the graph
List<Integer>[] graph = new LinkedList[numCourses];
for (int i = 0; i < numCourses; i++) {
graph[i] = new LinkedList<>();
}
for (int[] edge : prerequisites) {
int from = edge[1], to = edge[0];
// Add a directed edge from 'from' to 'to'
// The direction of the edge represents a dependency, i.e.,
// course 'to' can only be taken after course 'from'
graph[from].add(to);
}
return graph;
}vector<vector<int>> buildGraph(int numCourses, vector<vector<int>>& prerequisites) {
// There are numCourses nodes in the graph
vector<vector<int>> graph(numCourses);
for (int i = 0; i < numCourses; i++) {
graph[i] = vector<int>();
}
for (auto& edge : prerequisites) {
int from = edge[1], to = edge[0];
// Add a directed edge from 'from' to 'to'
// The direction of the edge represents a "dependency" relationship,
// meaning course 'to' can only be taken after completing course 'from'
graph[from].push_back(to);
}
return graph;
}from typing import List
def buildGraph(numCourses: int, prerequisites: List[List[int]]) -> List[List[int]]:
# there are numCourses nodes in the graph
graph = [[] for _ in range(numCourses)]
for edge in prerequisites:
from_, to_ = edge[1], edge[0]
# add a directed edge from from_ to to_
# the direction of the edge represents a "dependency",
# meaning you must complete course from_ before course to_
graph[from_].append(to_)
return graph// buildGraph constructs a directed graph
func buildGraph(numCourses int, prerequisites [][]int) []([]int) {
// the graph has numCourses nodes
graph := make([][]int, numCourses)
for i := 0; i < numCourses; i++ {
graph[i] = []int{}
}
for _, edge := range prerequisites {
from, to := edge[1], edge[0]
// add a directed edge from 'from' to 'to'
// the direction of the edge represents a dependency, meaning
// course 'to' can be taken only after course 'from'
graph[from] = append(graph[from], to)
}
return graph
}var buildGraph = function(numCourses, prerequisites) {
// there are numCourses nodes in the graph
var graph = new Array(numCourses);
for (var i = 0; i < numCourses; i++) {
graph[i] = [];
}
for (var j = 0; j < prerequisites.length; j++) {
var edge = prerequisites[j];
var from = edge[1], to = edge[0];
// add a directed edge from 'from' to 'to'
// the direction of the edge is the "dependency" relationship, meaning
// you must complete course 'from' before taking course 'to'
graph[from].push(to);
}
return graph;
}Now that we have constructed the graph, how do we check if there is a cycle in the graph?
It's very simple. The idea is to test your ability to traverse all paths in the graph. If I can traverse all the paths, then determining if a path forms a cycle becomes easy.
The article Graph Traversal with DFS/BFS explains how to use the DFS algorithm to traverse all paths in a graph. If you have forgotten, please review it because we will use it below.
Here, I will directly apply the DFS code template that traverses all paths. We will use a hasCycle variable to record whether there is a cycle. When we encounter a node that is already in the onPath set during traversal, it indicates a cycle, and we set hasCycle = true.
Based on this idea, let's look at the first version of the code (which might time out):
class Solution {
// record the nodes in the recursion stack
boolean[] onPath;
// record whether there is a cycle in the graph
boolean hasCycle = false;
public boolean canFinish(int numCourses, int[][] prerequisites) {
List<Integer>[] graph = buildGraph(numCourses, prerequisites);
onPath = new boolean[numCourses];
for (int i = 0; i < numCourses; i++) {
// traverse all the nodes in the graph
traverse(graph, i);
}
// as long as there are no cyclic dependencies, all courses can be finished
return !hasCycle;
}
// graph traversal function, traverse all paths
void traverse(List<Integer>[] graph, int s) {
if (hasCycle) {
// if a cycle has been found, no need to continue traversing
return;
}
if (onPath[s]) {
// s is already on the recursion path, indicating a cycle
hasCycle = true;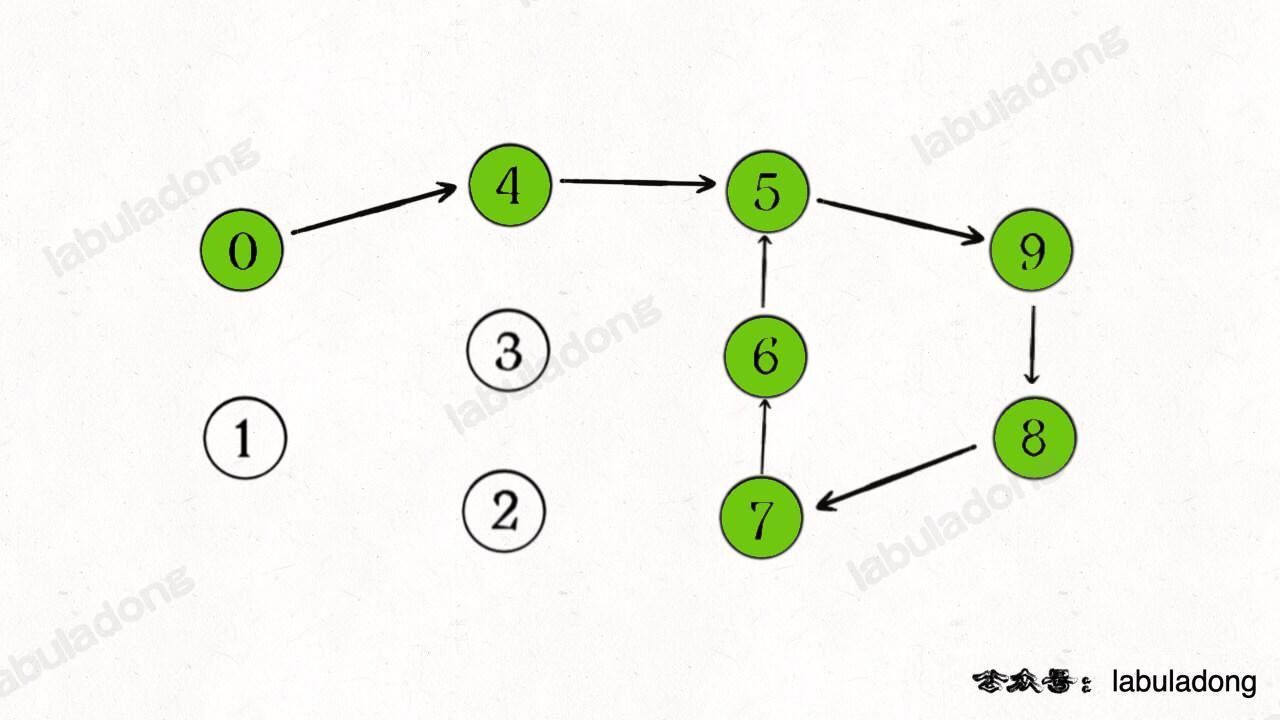 return;
}
// pre-order code position
onPath[s] = true;
for (int t : graph[s]) {
traverse(graph, t);
}
// post-order code position
onPath[s] = false;
}
List<Integer>[] buildGraph(int numCourses, int[][] prerequisites) {
// code as seen previously
}
}
return;
}
// pre-order code position
onPath[s] = true;
for (int t : graph[s]) {
traverse(graph, t);
}
// post-order code position
onPath[s] = false;
}
List<Integer>[] buildGraph(int numCourses, int[][] prerequisites) {
// code as seen previously
}
}class Solution {
public:
// record nodes in the recursion stack
vector<bool> onPath;
// record if there is a cycle in the graph
bool hasCycle = false;
bool canFinish(int numCourses, vector<vector<int>>& prerequisites) {
vector<vector<int>> graph = buildGraph(numCourses, prerequisites);
onPath = vector<bool>(numCourses);
for (int i = 0; i < numCourses; i++) {
// traverse all nodes in the graph
traverse(graph, i);
}
// as long as there are no cyclic dependencies, all courses can be completed
return !hasCycle;
}
// graph traversal function, traverse all paths
void traverse(vector<vector<int>>& graph, int s) {
if (hasCycle) {
// if a cycle has been found, no need to traverse further
return;
}
if (onPath[s]) {
// s is already on the recursion path, indicating a cycle
hasCycle = true;
return;
}
// pre-order code position
onPath[s] = true;
for (int t : graph[s]) {
traverse(graph, t);
}
// post-order code position
onPath[s] = false;
}
vector<vector<int>> buildGraph(int numCourses, vector<vector<int>>& prerequisites) {
// code see above
}
};class Solution:
def __init__(self):
# record nodes in the recursion stack
self.onPath = []
# record if there is a cycle in the graph
self.hasCycle = False
def canFinish(self, numCourses: int, prerequisites: List[List[int]]) -> bool:
graph = self.buildGraph(numCourses, prerequisites)
self.onPath = [False] * numCourses
for i in range(numCourses):
# traverse all nodes in the graph
self.traverse(graph, i)
# as long as there is no cyclic dependency, all courses can be finished
return not self.hasCycle
# graph traversal function, traverse all paths
def traverse(self, graph: List[List[int]], s: int):
if self.hasCycle:
# if a cycle has been found, no need to traverse further
return
if self.onPath[s]:
# s is already in the recursion path, indicating a cycle
self.hasCycle = True
return
# pre-order code position
self.onPath[s] = True
for t in graph[s]:
self.traverse(graph, t)
# post-order code position
self.onPath[s] = False
def buildGraph(self, numCourses: int, prerequisites: List[List[int]]) -> List[List[int]]:
# code see above
passfunc canFinish(numCourses int, prerequisites [][]int) bool {
// record nodes in the recursion stack
onPath := make([]bool, numCourses)
// record if there is a cycle in the graph
hasCycle := false
graph := buildGraph(numCourses, prerequisites)
for i := 0; i < numCourses; i++ {
// traverse all nodes in the graph
traverse(graph, i, &onPath, &hasCycle)
}
// as long as there is no cyclic dependency, all courses can be finished
return !hasCycle
}
// graph traversal function, traverse all paths
func traverse(graph [][]int, s int, onPath *[]bool, hasCycle *bool) {
if *hasCycle {
// if a cycle is found, no need to traverse further
return
}
if (*onPath)[s] {
// s is already on the recursion path, indicates a cycle
*hasCycle = true
return;
}
// pre-order position
(*onPath)[s] = true
for _, t := range graph[s] {
traverse(graph, t, onPath, hasCycle)
}
// post-order position
(*onPath)[s] = false
}
func buildGraph(numCourses int, prerequisites [][]int) [][]int {
// code as mentioned earlier
}var canFinish = function(numCourses, prerequisites) {
// record nodes in the recursion stack
var onPath = new Array(numCourses);
// record if there is a cycle in the graph
var hasCycle = false;
var graph = buildGraph(numCourses, prerequisites);
var traverse = function(graph, s) {
if (hasCycle) {
// if a cycle has been found, no need to traverse further
return;
}
if (onPath[s]) {
// s is already on the recursion path, indicating a cycle
hasCycle = true;
return;
}
// pre-order position
onPath[s] = true;
for (var t of graph[s]) {
traverse(graph, t);
}
// post-order position
onPath[s] = false;
}
for (var i = 0; i < numCourses; i++) {
// traverse all nodes in the graph
traverse(graph, i, onPath, hasCycle);
}
// as long as there are no cyclic dependencies, all courses can be completed
return !hasCycle;
}Note that not all nodes in the graph are connected, so we need to use a for loop to start a DFS search algorithm from every node.
This solution is actually correct because it traverses all paths and can definitely determine if there's a cycle. However, this solution cannot pass all test cases and will time out. The reason is quite obvious: there is redundant computation.
Where is the redundant computation? Let me give you an example to explain.
Suppose you start traversing all reachable paths from node 2 and eventually find no cycle.
Now, suppose there is an edge from another node 5 to node 2. When you start traversing all reachable paths from node 5, you will definitely reach node 2 again. So, do you need to continue traversing all paths from node 2?
The answer is no. If you didn't find a cycle the first time, you won't find one this time either. Do you understand the redundant computation here? If you think there might be a counterexample, you can try drawing it out. In reality, there is no counterexample.
So, the solution is straightforward: if we find a node that has already been visited, we can skip it and avoid redundant traversal.
Here is the optimized code:
class Solution {
// record nodes in the recursion stack
boolean[] onPath;
// record whether a node has been visited
boolean[] visited;
// record whether there is a cycle in the graph
boolean hasCycle = false;
public boolean canFinish(int numCourses, int[][] prerequisites) {
List<Integer>[] graph = buildGraph(numCourses, prerequisites);
onPath = new boolean[numCourses];
visited = new boolean[numCourses];
for (int i = 0; i < numCourses; i++) {
// traverse all nodes in the graph
traverse(graph, i);
}
// as long as there are no cyclic dependencies, all courses can be finished
return !hasCycle;
}
// graph traversal function, traverse all paths
void traverse(List<Integer>[] graph, int s) {
if (hasCycle) {
// if a cycle has been found, no need to traverse further
return;
}
if (onPath[s]) {
// s is already in the recursion path, indicating a cycle
hasCycle = true;
return;
}
if (visited[s]) {
// no need to traverse already visited nodes
return;
}
// pre-order code position
visited[s] = true;
onPath[s] = true;
for (int t : graph[s]) {
traverse(graph, t);
}
// post-order code position
onPath[s] = false;
}
List<Integer>[] buildGraph(int numCourses, int[][] prerequisites) {
// code as seen previously
}
}class Solution {
public:
// record nodes in the recursion stack
vector<bool> onPath;
// record whether nodes have been visited
vector<bool> visited;
// record whether there is a cycle in the graph
bool hasCycle = false;
bool canFinish(int numCourses, vector<vector<int>>& prerequisites) {
auto graph = buildGraph(numCourses, prerequisites);
onPath = vector<bool>(numCourses);
visited = vector<bool>(numCourses);
for (int i = 0; i < numCourses; i++) {
// traverse all nodes in the graph
traverse(graph, i);
}
// as long as there are no cyclic dependencies, all courses can be completed
return !hasCycle;
}
// graph traversal function, traverse all paths
void traverse(vector<vector<int>>& graph, int s) {
if (hasCycle) {
// if a cycle has been found, no need to traverse further
return;
}
if (onPath[s]) {
// s is already on the recursion path, indicating a cycle
hasCycle = true;
return;
}
if (visited[s]) {
// no need to traverse nodes that have already been visited
return;
}
// pre-order position
visited[s] = true;
onPath[s] = true;
for (int t : graph[s]) {
traverse(graph, t);
}
// post-order position
onPath[s] = false;
}
vector<vector<int>> buildGraph(int numCourses, vector<vector<int>>& prerequisites) {
// code as seen previously
}
};class Solution:
def __init__(self):
# record nodes in one recursion stack
self.onPath = []
# record whether a node has been visited
self.visited = []
# record whether there's a cycle in the graph
self.hasCycle = False
def canFinish(self, numCourses: int, prerequisites: List[List[int]]) -> bool:
graph = self.buildGraph(numCourses, prerequisites)
self.onPath = [False] * numCourses
self.visited = [False] * numCourses
for i in range(numCourses):
# traverse all nodes in the graph
self.traverse(graph, i)
# can finish all courses as long as there's no cyclic dependency
return not self.hasCycle
# graph traversal function, traverse all paths
def traverse(self, graph: List[List[int]], s: int):
if self.hasCycle:
# if a cycle has been found, no need to traverse further
return
if self.onPath[s]:
# s is already in the recursion path, indicating a cycle
self.hasCycle = True
return
if self.visited[s]:
# no need to traverse already visited nodes again
return
# pre-order code position
self.visited[s] = True
self.onPath[s] = True
for t in graph[s]:
self.traverse(graph, t)
# post-order code position
self.onPath[s] = False
def buildGraph(self, numCourses: int, prerequisites: List[List[int]]) -> List[List[int]]:
# code as seen previously
passfunc canFinish(numCourses int, prerequisites [][]int) bool {
// record nodes in the current recursion stack
onPath := make([]bool, numCourses)
// record whether the node has been visited
visited := make([]bool, numCourses)
// record whether there is a cycle in the graph
hasCycle := false
graph := buildGraph(numCourses, prerequisites)
for i := 0; i < numCourses; i++ {
// traverse all nodes in the graph
traverse(graph, i, &onPath, &visited, &hasCycle)
}
// as long as there are no cyclic dependencies, all courses can be completed
return !hasCycle
}
// graph traversal function, traverse all paths
func traverse(graph [][]int, s int, onPath *[]bool, visited *[]bool, hasCycle *bool) {
if *hasCycle {
// if a cycle has already been found, no need to traverse further
return
}
if (*onPath)[s] {
// s is already in the current recursion path, indicating a cycle
*hasCycle = true
return;
}
if (*visited)[s] {
// no need to traverse nodes that have already been visited
return
}
// pre-order code position
(*visited)[s] = true
(*onPath)[s] = true
for _, t := range graph[s] {
traverse(graph, t, onPath, visited, hasCycle)
}
// post-order code position
(*onPath)[s] = false
}
func buildGraph(numCourses int, prerequisites [][]int) [][]int {
// code as seen previously
}var canFinish = function(numCourses, prerequisites) {
// record nodes in the current recursion stack
let onPath = new Array(numCourses);
// record whether a node has been visited
let visited = new Array(numCourses);
// record whether there is a cycle in the graph
let hasCycle = false;
let graph = buildGraph(numCourses, prerequisites);
let traverse = function(graph, s) {
if (hasCycle) {
// if a cycle is found, no need to traverse further
return;
}
if (onPath[s]) {
// s is already in the recursion path, indicating a cycle
hasCycle = true;
return;
}
if (visited[s]) {
// no need to traverse nodes that have already been visited
return;
}
// pre-order code position
visited[s] = true;
onPath[s] = true;
for (let t of graph[s]) {
traverse(graph, t);
}
// post-order code position
onPath[s] = false;
}
for (let i = 0; i < numCourses; i++) {
// traverse all nodes in the graph
traverse(graph, i, onPath, visited, hasCycle);
}
// as long as there are no cyclic dependencies, all courses can be completed
return !hasCycle;
}
var buildGraph = function(numCourses, prerequisites) {
// code as seen earlier
}Nodes with visited set to true are green, and nodes with onPath set to true are orange.
You can open the visualization panel and repeatedly click the if (onPath[s]) part of the code to observe the DFS traversal process.
Algorithm Visualization
This problem is solved by determining whether there is a cycle in a directed graph.
However, if the interviewer asks further, requiring you not only to detect the existence of a cycle but also to return the specific nodes forming the cycle, what should you do?
You might think that the indices in onPath with true values are the nodes forming the cycle, right?
That's not correct. Assume traversal starts from node 0, the green nodes in the figure below represent the recursive path, and they all have true values in onPath, but clearly, only part of them actually form the cycle:
You can take a moment to think about this problem, as there are many potential solutions. I will provide a common method.
Click to view the answer
The simplest and most direct solution is to use a Stack<Integer> path along with the boolean[] onPath array, to keep track of the order of nodes traversed.
For example, following the green traversal order in the figure above, the elements in path from bottom to top would be [0,4,5,9,8,7,6]. Upon encountering node 5 again, you can identify that [5,9,8,7,6] forms the cycle.
Next, let's discuss a classic graph algorithm: Topological Sorting.
Topological Sorting Algorithm (DFS Version)
Consider LeetCode Problem 210: "Course Schedule II":
210. Course Schedule II | LeetCode | 🟠
There are a total of numCourses courses you have to take, labeled from 0 to numCourses - 1. You are given an array prerequisites where prerequisites[i] = [ai, bi] indicates that you must take course bi first if you want to take course ai.
- For example, the pair
[0, 1], indicates that to take course0you have to first take course1.
Return the ordering of courses you should take to finish all courses. If there are many valid answers, return any of them. If it is impossible to finish all courses, return an empty array.
Example 1:
Input: numCourses = 2, prerequisites = [[1,0]] Output: [0,1] Explanation: There are a total of 2 courses to take. To take course 1 you should have finished course 0. So the correct course order is [0,1].
Example 2:
Input: numCourses = 4, prerequisites = [[1,0],[2,0],[3,1],[3,2]] Output: [0,2,1,3] Explanation: There are a total of 4 courses to take. To take course 3 you should have finished both courses 1 and 2. Both courses 1 and 2 should be taken after you finished course 0. So one correct course order is [0,1,2,3]. Another correct ordering is [0,2,1,3].
Example 3:
Input: numCourses = 1, prerequisites = [] Output: [0]
Constraints:
1 <= numCourses <= 20000 <= prerequisites.length <= numCourses * (numCourses - 1)prerequisites[i].length == 20 <= ai, bi < numCoursesai != bi- All the pairs
[ai, bi]are distinct.
This problem builds upon the previous one, requiring not only determining if all courses can be completed but also returning a valid course order, ensuring all prerequisite courses are completed before starting each course.
The function signature is as follows:
int[] findOrder(int numCourses, int[][] prerequisites);vector<int> findOrder(int numCourses, vector<vector<int>>& prerequisites);def findOrder(numCourses: int, prerequisites: List[List[int]]) -> List[int]:func findOrder(numCourses int, prerequisites [][]int) []intvar findOrder = function(numCourses, prerequisites) {};Here, I will first introduce the term topological sorting. The definitions found online are quite mathematical, so let's use an image from Baidu Encyclopedia to give you an intuitive feel:
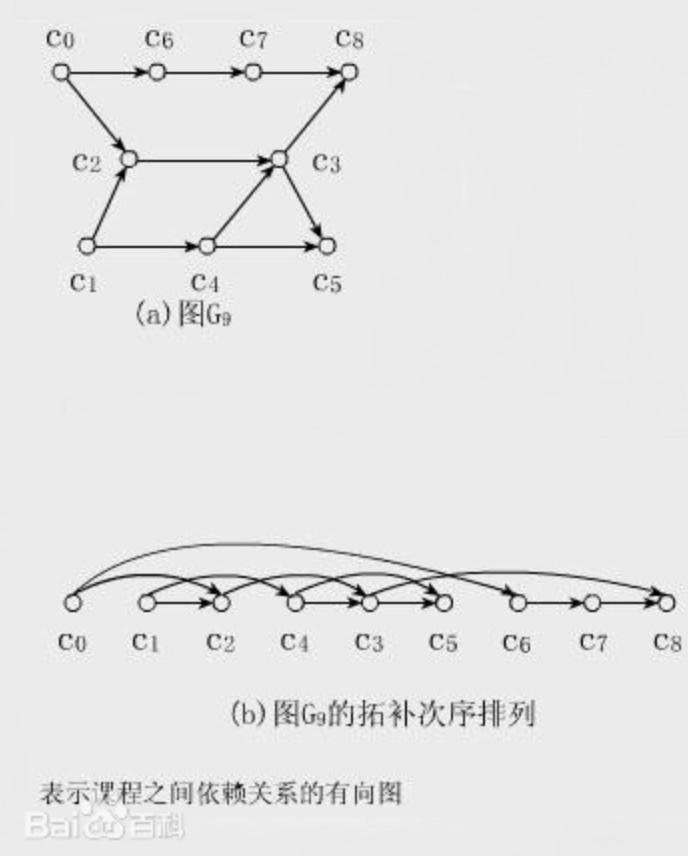
Simply put, it means flattening a graph in such a way that all the arrows point in the same direction, like in the above image where all arrows point to the right.
Obviously, if a directed graph contains a cycle, topological sorting is impossible, as it is not feasible to have all arrows pointing in the same direction. Conversely, if a graph is a "Directed Acyclic Graph" (DAG), then topological sorting is always possible.
But what does this have to do with our problem?
It's not hard to see that if you abstract courses as nodes and the dependencies between courses as directed edges, then the result of the topological sort of this graph is the course order.
First, we need to determine if the course dependencies provided in the problem form a cycle. If they do, topological sorting is impossible. Therefore, we can reuse the main function from the previous problem:
public int[] findOrder(int numCourses, int[][] prerequisites) {
if (!canFinish(numCourses, prerequisites)) {
// not possible to finish all courses
return new int[]{};
}
// ...
}vector<int> findOrder(int numCourses, vector<vector<int>>& prerequisites) {
if (!canFinish(numCourses, prerequisites)) {
// impossible to finish all courses
return vector<int>();
}
// ...
}def findOrder(numCourses: int, prerequisites: List[List[int]]) -> List[int]:
if not canFinish(numCourses, prerequisites):
# It's not possible to complete all courses
return []
# ...func findOrder(numCourses int, prerequisites [][]int) []int {
if !canFinish(numCourses, prerequisites) {
// impossible to finish all courses
return []int{}
}
// ...
}var findOrder = function(numCourses, prerequisites) {
if (!canFinish(numCourses, prerequisites)) {
// impossible to complete all courses
return [];
}
// ...
}So, the key question is, how do we perform topological sorting? Do we need to use some advanced techniques again?
Actually, it's quite simple. Just reverse the result of a post-order traversal of the graph, and you'll get the topological sort result.
Do we need to reverse?
Some readers mention that they have seen topological sorting algorithms online that use the post-order traversal result without reversing it. Why is that?
You can indeed find such solutions. The reason is that the way they define the edges while constructing the graph is different from mine. In my graph, the direction of the arrow represents the "dependency" relationship. For example, if node 1 points to node 2, it means that node 1 is depended on by node 2, i.e., you must complete 1 before you can do 2, which aligns more with our intuition.
If you reverse this and define directed edges as "dependencies," then all edges in the entire graph are reversed, and you don't need to reverse the post-order traversal result. Specifically, you can change graph[from].add(to); in my solution to graph[to].add(from); to avoid reversing the result.
Let's look at the solution code. It builds on the cycle detection code by adding the logic to record the post-order traversal result:
class Solution {
// record the postorder traversal result
List<Integer> postorder = new ArrayList<>();
// record if a cycle exists
boolean hasCycle = false;
boolean[] visited, onPath;
// main function
public int[] findOrder(int numCourses, int[][] prerequisites) {
List<Integer>[] graph = buildGraph(numCourses, prerequisites);
visited = new boolean[numCourses];
onPath = new boolean[numCourses];
// traverse the graph
for (int i = 0; i < numCourses; i++) {
traverse(graph, i);
}
// cannot perform topological sort if there is a cycle
if (hasCycle) {
return new int[]{};
}
// reverse postorder traversal result is the topological sort result
Collections.reverse(postorder);
int[] res = new int[numCourses];
for (int i = 0; i < numCourses; i++) {
res[i] = postorder.get(i);
}
return res;
}
// graph traversal function
void traverse(List<Integer>[] graph, int s) {
if (onPath[s]) {
// found a cycle
hasCycle = true;
}
if (visited[s] || hasCycle) {
return;
}
// pre-order traversal position
onPath[s] = true;
visited[s] = true;
for (int t : graph[s]) {
traverse(graph, t);
}
// post-order traversal position
postorder.add(s);
onPath[s] = false;
}
// build graph function
List<Integer>[] buildGraph(int numCourses, int[][] prerequisites) {
// code as seen earlier
}
}class Solution {
public:
// record postorder traversal result
vector<int> postorder;
// record if there is a cycle
bool hasCycle = false;
vector<bool> visited, onPath;
// main function
vector<int> findOrder(int numCourses, vector<vector<int>>& prerequisites) {
vector<int>* graph = buildGraph(numCourses, prerequisites);
visited = vector<bool>(numCourses);
onPath = vector<bool>(numCourses);
// traverse the graph
for (int i = 0; i < numCourses; i++) {
traverse(graph, i);
}
// graph with a cycle cannot have a topological sort
if (hasCycle) {
return vector<int>();
}
// reverse postorder traversal result is the topological sort result
reverse(postorder.begin(), postorder.end());
return postorder;
}
// graph traversal function
void traverse(vector<int>* graph, int s) {
if (onPath[s]) {
// cycle found
hasCycle = true;
}
if (visited[s] || hasCycle) {
return;
}
// pre-order traversal position
onPath[s] = true;
visited[s] = true;
for (int t : graph[s]) {
traverse(graph, t);
}
// post-order traversal position
postorder.push_back(s);
onPath[s] = false;
}
// graph building function
vector<int> buildGraph(int numCourses, vector<vector<int>>& prerequisites) {
// code as per previous text
}
};class Solution:
def __init__(self):
# record postorder traversal result
self.postorder = []
# record if there is a cycle
self.hasCycle = False
self.visited = []
self.onPath = []
def findOrder(self, numCourses: int, prerequisites: List[List[int]]) -> List[int]:
graph = self.buildGraph(numCourses, prerequisites)
self.visited = [False] * numCourses
self.onPath = [False] * numCourses
# traverse the graph
for i in range(numCourses):
self.traverse(graph, i)
# cannot perform topological sort if there's a cycle
if self.hasCycle:
return []
# reverse postorder traversal result is the topological sort result
self.postorder.reverse()
return self.postorder
# graph traversal function
def traverse(self, graph: List[List[int]], s: int):
if self.onPath[s]:
# found a cycle
self.hasCycle = True
if self.visited[s] or self.hasCycle:
return
# pre-order traversal position
self.onPath[s] = True
self.visited[s] = True
for t in graph[s]:
self.traverse(graph, t)
# post-order traversal position
self.postorder.append(s)
self.onPath[s] = False
# build graph function
def buildGraph(self, numCourses: int, prerequisites: List[List[int]]) -> List[List[int]]:
# code as described above
passfunc findOrder(numCourses int, prerequisites [][]int) []int {
graph := buildGraph(numCourses, prerequisites)
visited := make([]bool, numCourses)
onPath := make([]bool, numCourses)
postorder := make([]int, 0)
hasCycle := false
// traverse the graph
for i := 0; i < numCourses; i++ {
traverse(graph, i, &onPath, &visited, &postorder, &hasCycle)
}
// cannot perform topological sort on a graph with a cycle
if hasCycle {
return []int{}
}
// reverse postorder result is the topological sort result
reverse(postorder)
return postorder
}
// graph traversal function
func traverse(graph [][]int, s int, onPath *[]bool, visited *[]bool, postorder *[]int, hasCycle *bool) {
if (*onPath)[s] {
// cycle detected
*hasCycle = true
}
if (*visited)[s] || *hasCycle {
return
}
// pre-order position
(*onPath)[s] = true
(*visited)[s] = true
for _, t := range graph[s] {
traverse(graph, t, onPath, visited, postorder, hasCycle)
}
// post-order position
*postorder = append(*postorder, s)
(*onPath)[s] = false
}
func reverse(arr []int) {
i, j := 0, len(arr)-1
for i < j {
arr[i], arr[j] = arr[j], arr[i]
i++
j--
}
}
// build graph function
func buildGraph(numCourses int, prerequisites [][]int) [][]int {
// code as seen earlier
}var findOrder = function(numCourses, prerequisites) {
// record postorder traversal result
let postorder = [];
// record if there is a cycle
let hasCycle = false;
let visited = new Array(numCourses);
let onPath = new Array(numCourses);
let graph = buildGraph(numCourses, prerequisites);
let traverse = function(graph, s) {
if (onPath[s]) {
// cycle detected
hasCycle = true;
}
if (visited[s] || hasCycle) {
return;
}
// pre-order position
onPath[s] = true;
visited[s] = true;
for (let t of graph[s]) {
traverse(graph, t);
}
// post-order position
postorder.push(s);
onPath[s] = false;
}
for (let i = 0; i < numCourses; i++) {
// traverse the graph
traverse(graph, i);
}
// cannot perform topological sort on a graph with a cycle
if (hasCycle) {
return [];
}
// reverse postorder result is the topological sort result
postorder.reverse();
return postorder;
}
var buildGraph = function(numCourses, prerequisites) {
// code as seen earlier
}Nodes with visited set to true are green, and nodes with onPath set to true are orange.
You can open the visualization panel and repeatedly click on the if (onPath[s]) code section to observe the DFS traversal process.
Algorithm Visualization
Although the code may seem lengthy, the logic should be clear. As long as the graph is acyclic, we invoke the traverse function to perform DFS traversal on the graph, recording the post-order traversal result, and then reverse this result to get the final answer.
Why is the reversed post-order traversal result a topological sort?
Here, instead of a mathematical proof, I will use an intuitive example to explain. Let's talk about binary trees, referring to our frequently discussed binary tree traversal framework:
void traverse(TreeNode root) {
// pre-order traversal position
traverse(root.left)
// in-order traversal position
traverse(root.right)
// post-order traversal position
}void traverse(TreeNode* root) {
// pre-order traversal code goes here
traverse(root->left);
// in-order traversal code goes here
traverse(root->right);
// post-order traversal code goes here
}def traverse(root: TreeNode):
# code position for pre-order traversal
traverse(root.left)
# code position for in-order traversal
traverse(root.right)
# code position for post-order traversalfunc traverse(root *TreeNode) {
// pre-order traversal code location
traverse(root.left)
// in-order traversal code location
traverse(root.right)
// post-order traversal code location
}var traverse = function(root){
// pre-order traversal code location
traverse(root.left);
// in-order traversal code location
traverse(root.right);
// post-order traversal code location
}When does post-order traversal occur in a binary tree? It happens after traversing the left and right subtrees, at which point the code for the post-order position is executed. In other words, the root node is added to the result list only after the nodes of the left and right subtrees have been added.
This characteristic of post-order traversal is crucial because the basis of topological sorting is post-order traversal. A task must wait until all its dependent tasks are completed before it can start execution.
If you think of a binary tree as a directed graph, where the direction of the edges is from the parent node to the child node, it looks like this:
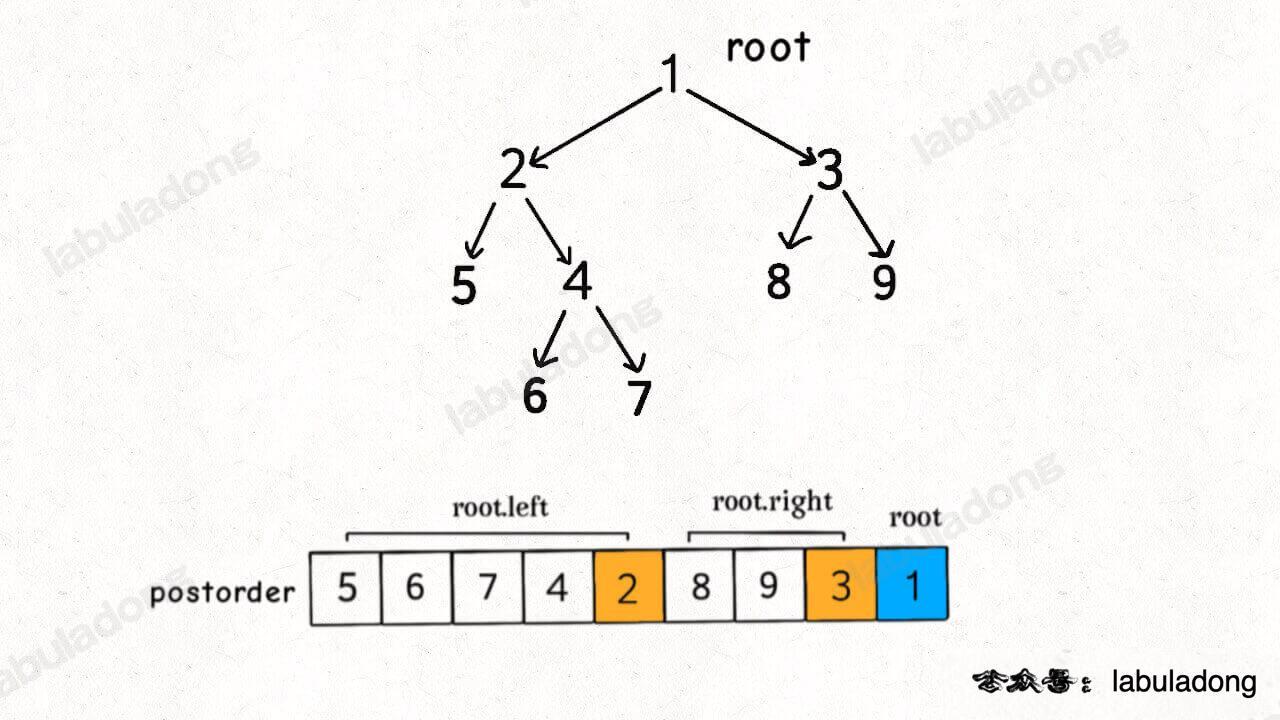
For a standard post-order traversal, the root node appears last. By reversing the traversal result, you get the topological sort result:
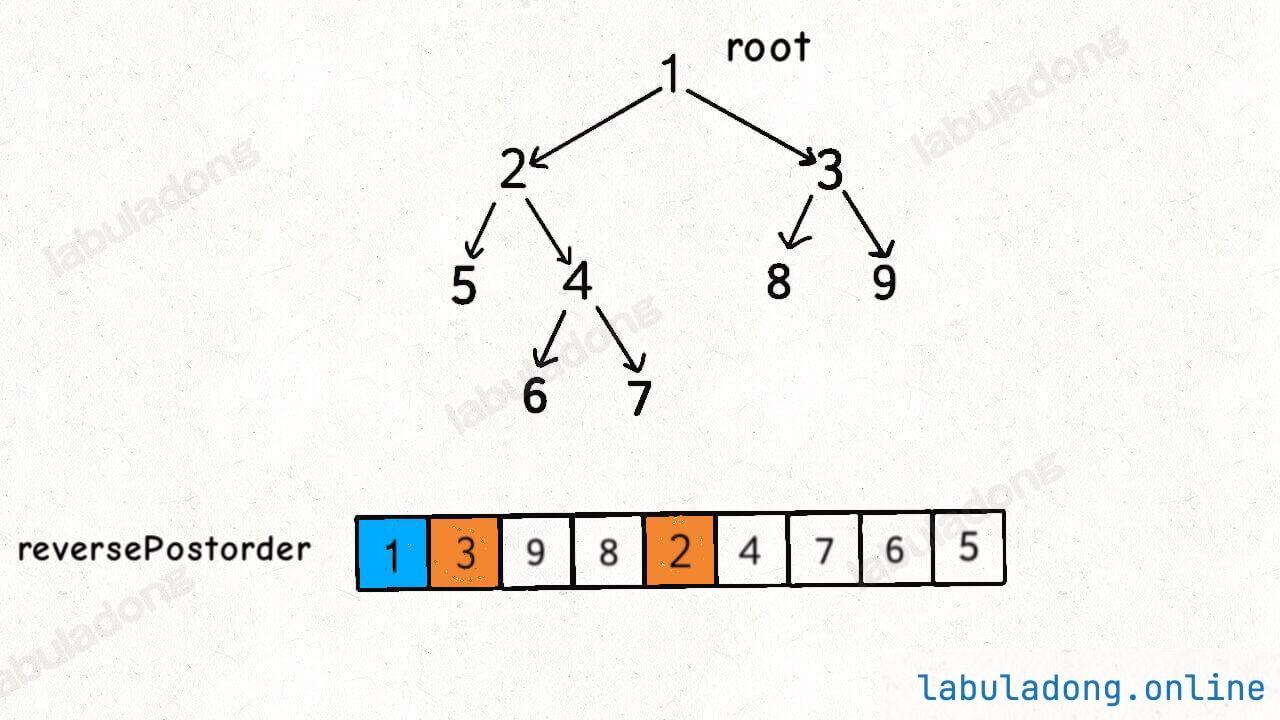
I know some readers might ask what the relationship is between the reversed post-order traversal result and the pre-order traversal result.
For binary trees, it might seem like there is a connection, but in reality, there is none. Do not assume that the reversed post-order result is equivalent to the pre-order traversal result.
Their key differences have been discussed in Binary Tree Concepts (Overview). The code in the post-order position is executed only after both the left and right subtrees have been traversed, which is the only way to reflect the "dependency" relationship, something other traversal orders cannot achieve.
Cycle Detection Algorithm (BFS Version)
Earlier, we discussed using the DFS algorithm with the onPath array to determine if a cycle exists; we also talked about using DFS with reverse postorder traversal for topological sorting.
In fact, the BFS algorithm can achieve these two tasks by using the indegree array to record the "in-degree" of each node. If you are not familiar with BFS, you can read the previous article Core Framework of BFS Algorithm.
The concepts of "out-degree" and "in-degree" are intuitive in directed graphs: if a node x has a edges pointing to other nodes and is pointed to by b edges, then node x has an out-degree of a and an in-degree of b.
Let's start with the cycle detection algorithm and directly look at the BFS solution code:
class Solution {
public boolean canFinish(int numCourses, int[][] prerequisites) {
// build the graph, directed edges represent "dependency" relationship
List<Integer>[] graph = buildGraph(numCourses, prerequisites);
// construct the indegree array
int[] indegree = new int[numCourses];
for (int[] edge : prerequisites) {
int from = edge[1], to = edge[0];
// increase the indegree of node 'to'
indegree[to]++;
}
// initialize the queue with nodes having zero indegree
Queue<Integer> q = new LinkedList<>();
for (int i = 0; i < numCourses; i++) {
if (indegree[i] == 0) {
// node 'i' has no indegree, i.e., no dependencies
// can be used as a starting point for topological sort, add to queue
q.offer(i);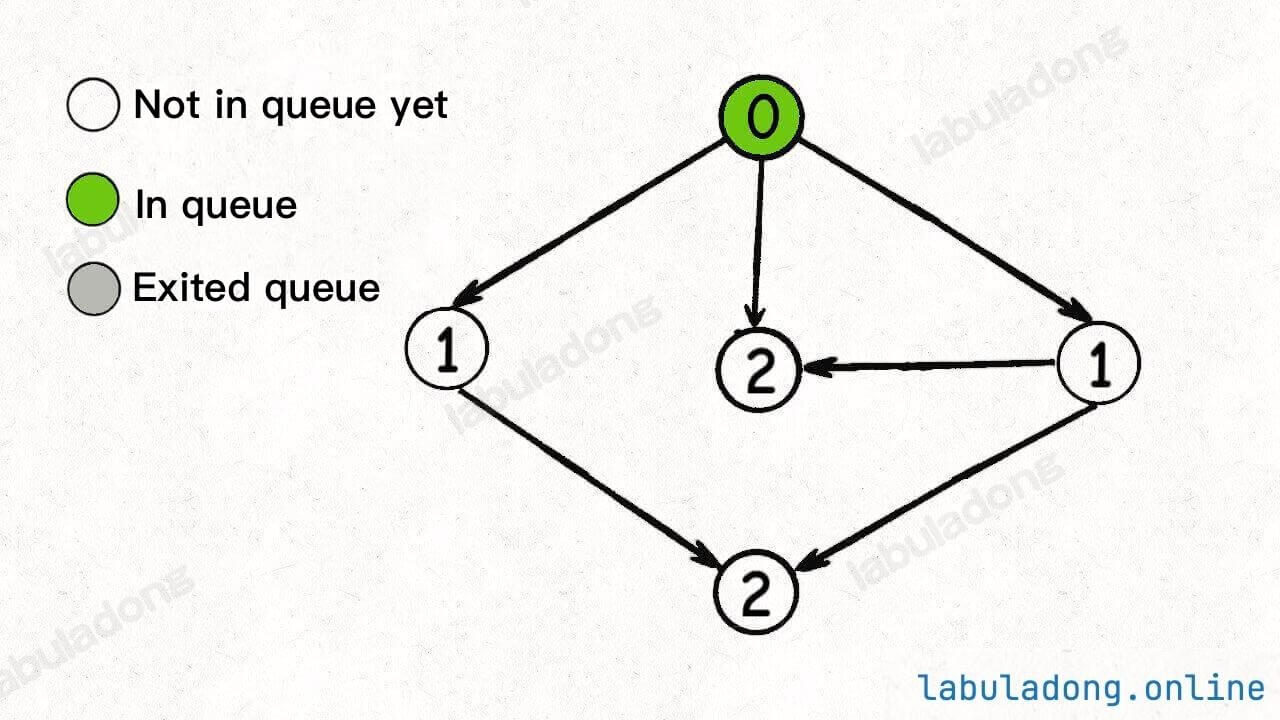 }
}
// record the number of nodes traversed
int count = 0;
// start the BFS loop
while (!q.isEmpty()) {
// dequeue node 'cur' and decrease the indegree of its adjacent nodes
int cur = q.poll();
count++;
for (int next : graph[cur]) {
}
}
// record the number of nodes traversed
int count = 0;
// start the BFS loop
while (!q.isEmpty()) {
// dequeue node 'cur' and decrease the indegree of its adjacent nodes
int cur = q.poll();
count++;
for (int next : graph[cur]) {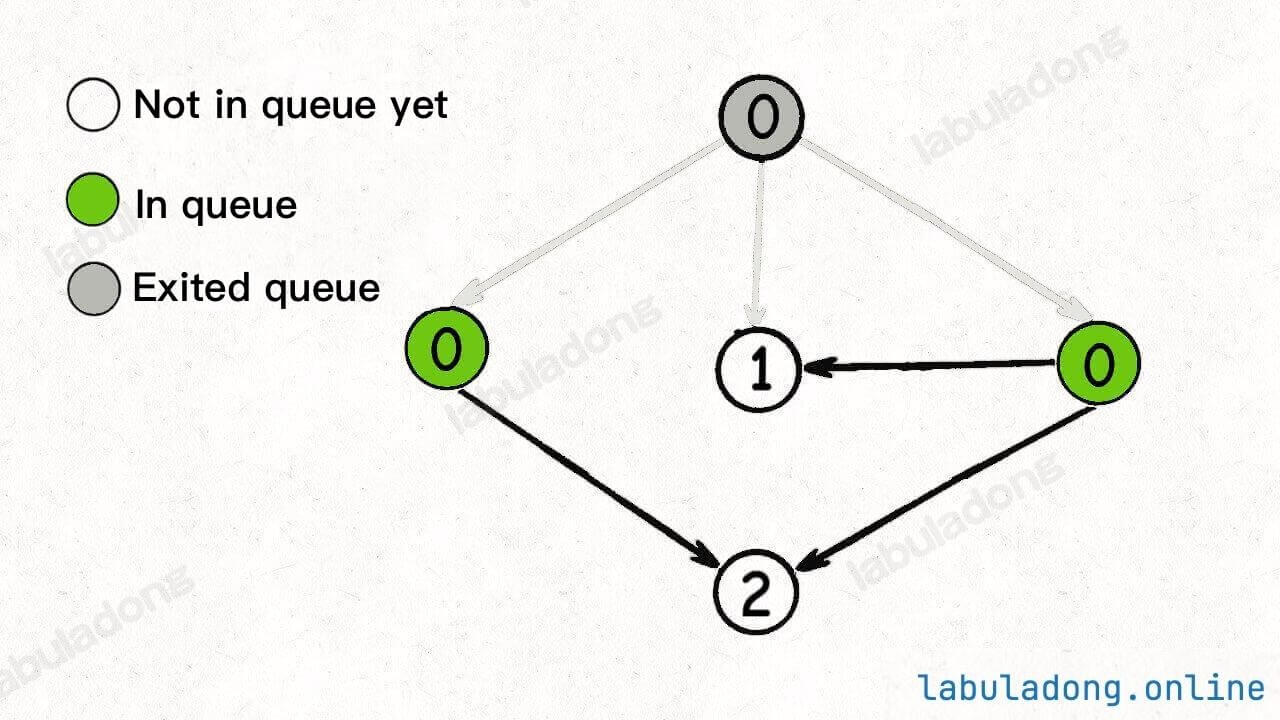 indegree[next]--;
if (indegree[next] == 0) {
// if the indegree becomes zero, it means all
// dependencies of 'next' have been visited
q.offer(next);
}
}
}
// if all nodes have been traversed, it means there is no cycle
return count == numCourses;
}
// function to build the graph
List<Integer>[] buildGraph(int n, int[][] edges) {
// see above
}
}
indegree[next]--;
if (indegree[next] == 0) {
// if the indegree becomes zero, it means all
// dependencies of 'next' have been visited
q.offer(next);
}
}
}
// if all nodes have been traversed, it means there is no cycle
return count == numCourses;
}
// function to build the graph
List<Integer>[] buildGraph(int n, int[][] edges) {
// see above
}
}class Solution {
public:
bool canFinish(int numCourses, vector<vector<int>>& prerequisites) {
// build the graph, directed edges represent "dependency" relationship
vector<int>* graph = buildGraph(numCourses, prerequisites);
// build the indegree array
vector<int> indegree(numCourses);
for (auto& edge : prerequisites) {
int from = edge[1], to = edge[0];
// increment the indegree of node 'to'
indegree[to]++;
}
// initialize the queue with nodes having zero indegree
queue<int> q;
for (int i = 0; i < numCourses; i++) {
if (indegree[i] == 0) {
// node i has zero indegree, i.e., no dependencies
// can be used as a starting point for topological sort, add to queue
q.push(i);
}
}
// count the number of visited nodes
int count = 0;
// start the BFS loop
while (!q.empty()) {
// pop node 'cur' and decrement the indegree of its neighboring nodes
int cur = q.front();
q.pop();
count++;
for (int next : graph[cur]) {
indegree[next]--;
if (indegree[next] == 0) {
// if indegree becomes zero, it means all dependencies of 'next' are visited
q.push(next);
}
}
}
// if all nodes are visited, there is no cycle
return count == numCourses;
}
// function to build the graph
vector<int>* buildGraph(int n, vector<vector<int>>& edges) {
// see above
}
};class Solution:
def canFinish(self, numCourses: int, prerequisites: List[List[int]]) -> bool:
# Build the graph, directed edges represent "dependency" relationships
graph = self.buildGraph(numCourses, prerequisites)
# Construct the indegree array
indegree = [0] * numCourses
for edge in prerequisites:
from_, to = edge[1], edge[0]
# Increase the indegree of node 'to' by one
indegree[to] += 1
# Initialize the queue with nodes based on their indegree
q = collections.deque()
for i in range(numCourses):
if indegree[i] == 0:
# Node i has no indegree, meaning it has no dependencies
# It can be used as a starting point for
# topological sorting, add it to the queue
q.append(i)
# Record the number of nodes traversed
count = 0
# Start the BFS loop
while q:
# Pop node cur and decrease the indegree of its adjacent nodes by one
cur = q.popleft()
count += 1
for next_ in graph[cur]:
indegree[next_] -= 1
if indegree[next_] == 0:
# If the indegree becomes 0, it indicates all nodes that
# next depends on have been traversed
q.append(next_)
# If all nodes have been traversed, it indicates there is no cycle
return count == numCourses
# Build graph function
def buildGraph(self, n, edges):
# See previous text
passfunc canFinish(numCourses int, prerequisites [][]int) bool {
// build the graph, directed edges represent "dependency" relationships
graph := buildGraph(numCourses, prerequisites)
// build the indegree array
indegree := make([]int, numCourses)
for _, edge := range prerequisites {
to := edge[0]
// increase the indegree of node 'to' by one
indegree[to]++
}
// initialize the queue with nodes based on their indegree
q := make([]int, 0)
for i := 0; i < numCourses; i++ {
if indegree[i] == 0 {
// node 'i' has no indegree, i.e., no dependencies
// it can be used as the starting point of topological sorting, add to queue
q = append(q, i)
}
}
// record the number of nodes traversed
count := 0
// start the BFS loop
for len(q) > 0 {
// dequeue node 'cur' and decrease the indegree of its adjacent nodes by one
cur := q[0]
q = q[1:]
count++
for _, next := range graph[cur] {
indegree[next]--
if indegree[next] == 0 {
// if indegree becomes 0, it means all nodes that
// 'next' depends on have been traversed
q = append(q, next)
}
}
}
// if all nodes have been traversed, it means there is no cycle
return count == numCourses
}
// build graph function
func buildGraph(numCourses int, prerequisites [][]int) [][]int {
// see previous text
}var canFinish = function(numCourses, prerequisites) {
// build the graph, directed edges represent "dependency" relationships
let graph = buildGraph(numCourses, prerequisites);
// construct the indegree array
let indegree = new Array(numCourses).fill(0);
for (let edge of prerequisites) {
let to = edge[0];
// increment the indegree of node 'to'
indegree[to]++;
}
// initialize the queue with nodes based on their indegree
let q = [];
for (let i = 0; i < numCourses; i++) {
if (indegree[i] === 0) {
// node 'i' has no indegree, meaning it has no dependencies
// can be used as a starting point for topological sorting, add to queue
q.push(i);
}
}
// record the number of nodes traversed
let count = 0;
// start the BFS loop
while (q.length) {
// dequeue node cur and decrement the indegree of nodes it points to
let cur = q.shift();
count++;
for (let next of graph[cur]) {
indegree[next]--;
if (indegree[next] === 0) {
// if indegree becomes 0, it means all nodes next depends on have been visited
q.push(next);
}
}
}
// if all nodes have been traversed, it means there is no cycle
return count === numCourses;
}
// function to build the graph
function buildGraph(n, edges) {
// see previous text
}Let me summarize the idea of this BFS algorithm:
Construct an adjacency list, where the direction of the edges indicates the "dependency" relationship.
Create an
indegreearray to record the indegree of each node, meaningindegree[i]records the indegree of nodei.Initialize the BFS queue by adding nodes with an indegree of 0 first.
4. Begin the BFS loop, continuously dequeue nodes, reduce the indegree of adjacent nodes, and add nodes with a newly reduced indegree of 0 to the queue.
5. If eventually all nodes have been traversed (count equals the number of nodes), it indicates there is no cycle; otherwise, a cycle exists.
Here's a diagram to help you understand. In the following image, the numbers within the nodes represent their indegrees:
After initializing the queue, nodes with an indegree of 0 are added to the queue first:
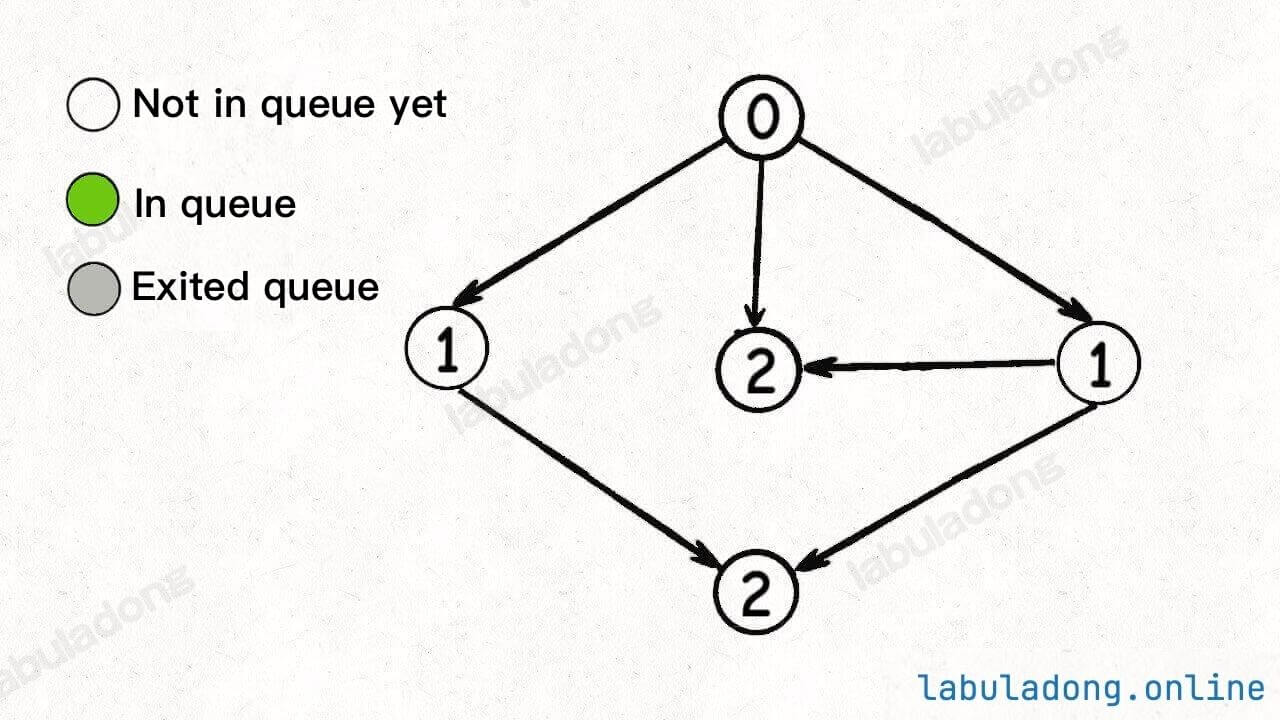
Start executing the BFS loop, dequeue a node, decrease the indegree of its adjacent nodes, and add any newly resulting nodes with an indegree of 0 to the queue:
Continue dequeuing nodes and reducing the indegree of adjacent nodes. This time, no new nodes with an indegree of 0 are generated:
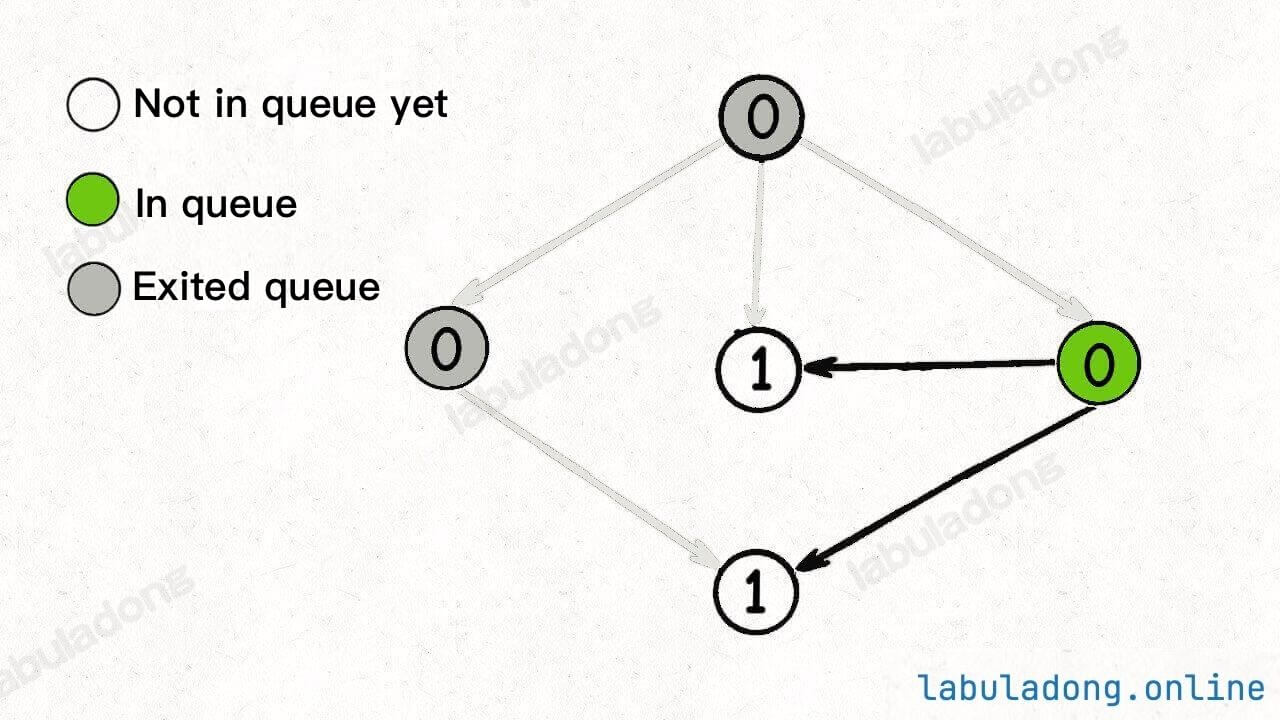
Keep dequeuing nodes, reducing indegrees, and adding any newly generated nodes with an indegree of 0 to the queue:
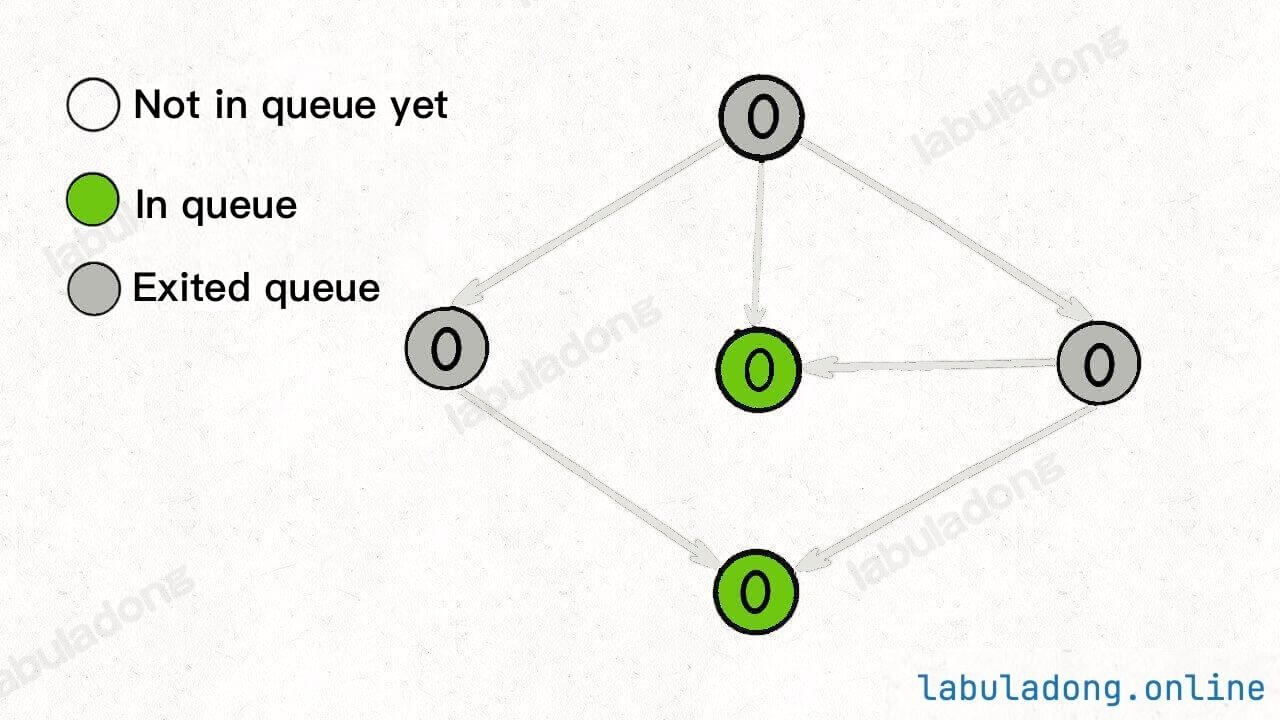
Continue dequeuing nodes until the queue is empty:
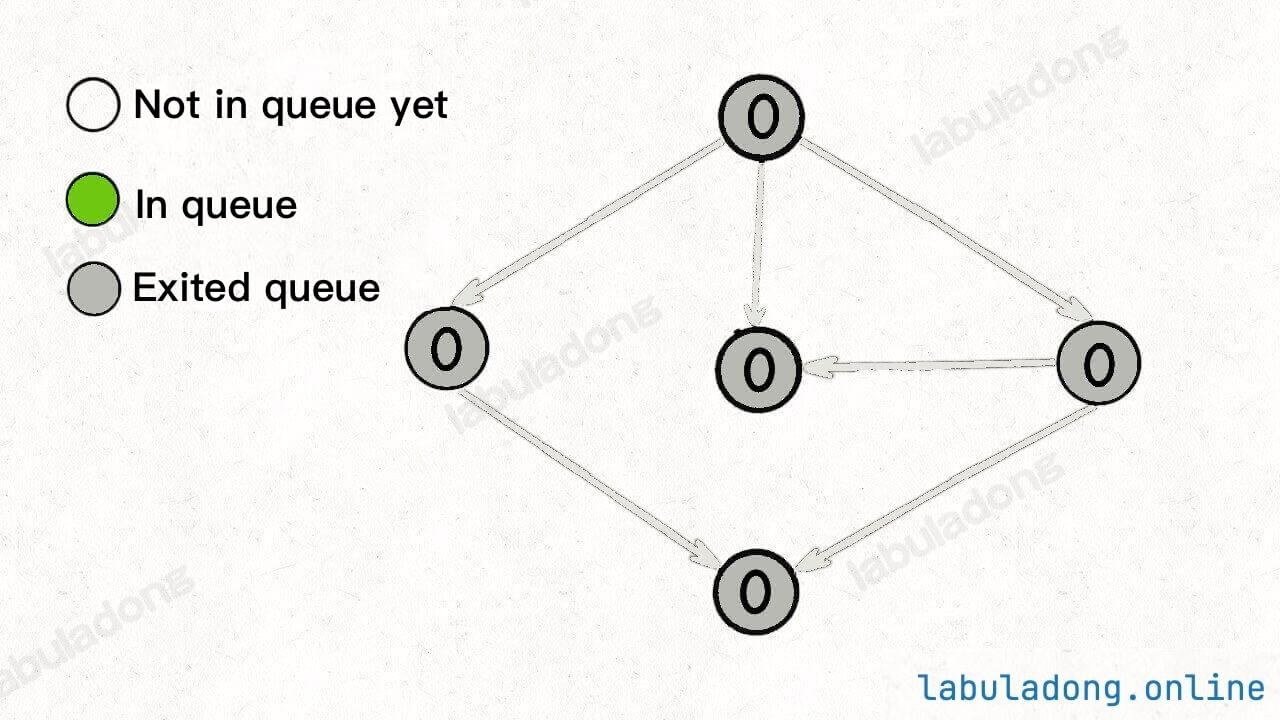
At this point, all nodes have been traversed, indicating that there is no cycle in the graph.
Conversely, if there are untraversed nodes after applying the BFS algorithm as described, a cycle exists.
For example, in the scenario below, the queue initially contains only one node with an indegree of 0:
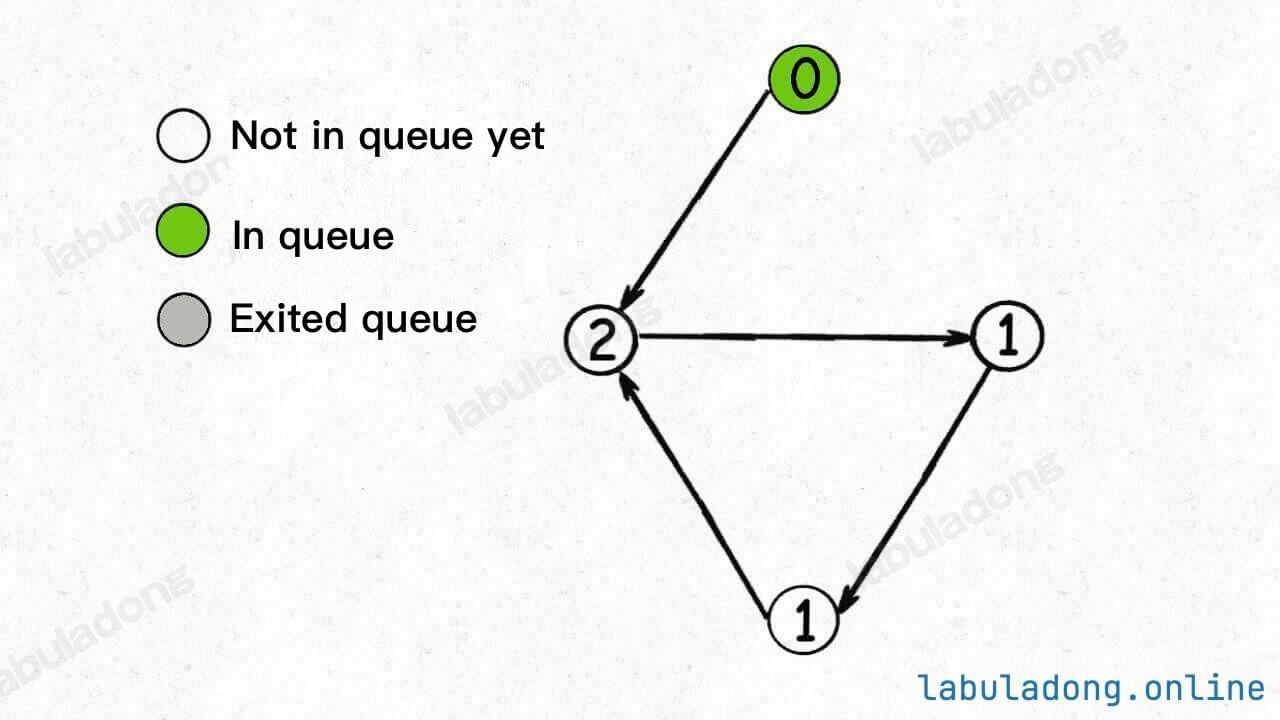
After dequeuing this node and reducing the indegree of the adjacent nodes, the queue becomes empty, and no new nodes with an indegree of 0 are added, causing the BFS algorithm to terminate:
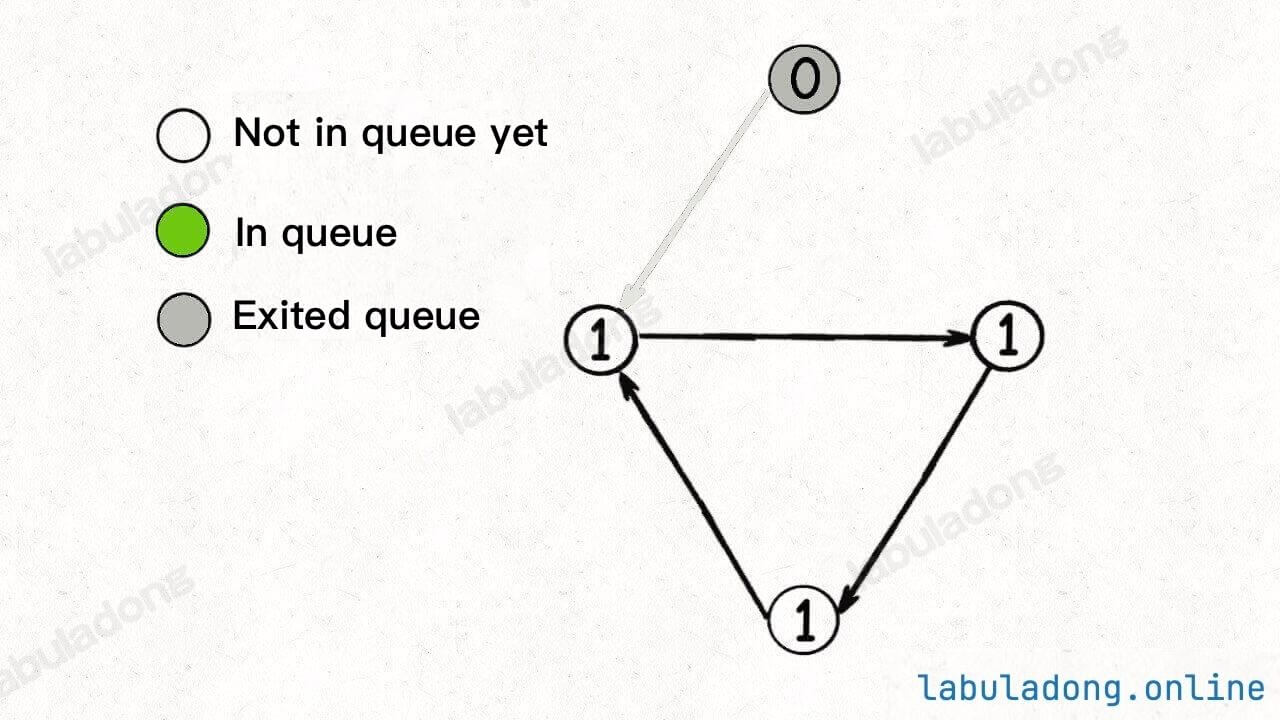
As you can see, if any nodes remain untraversed, it indicates a cycle in the graph. Now, if you review the BFS code, you should find the logic easier to comprehend.
Topological Sorting Algorithm (BFS Version)
If you understand the cycle detection algorithm using BFS, you can easily grasp the BFS version of the topological sorting algorithm, as the order in which nodes are traversed is the result of the topological sort.
For example, in the first example mentioned earlier, the value in each node in the diagram below represents the order in which they are queued:
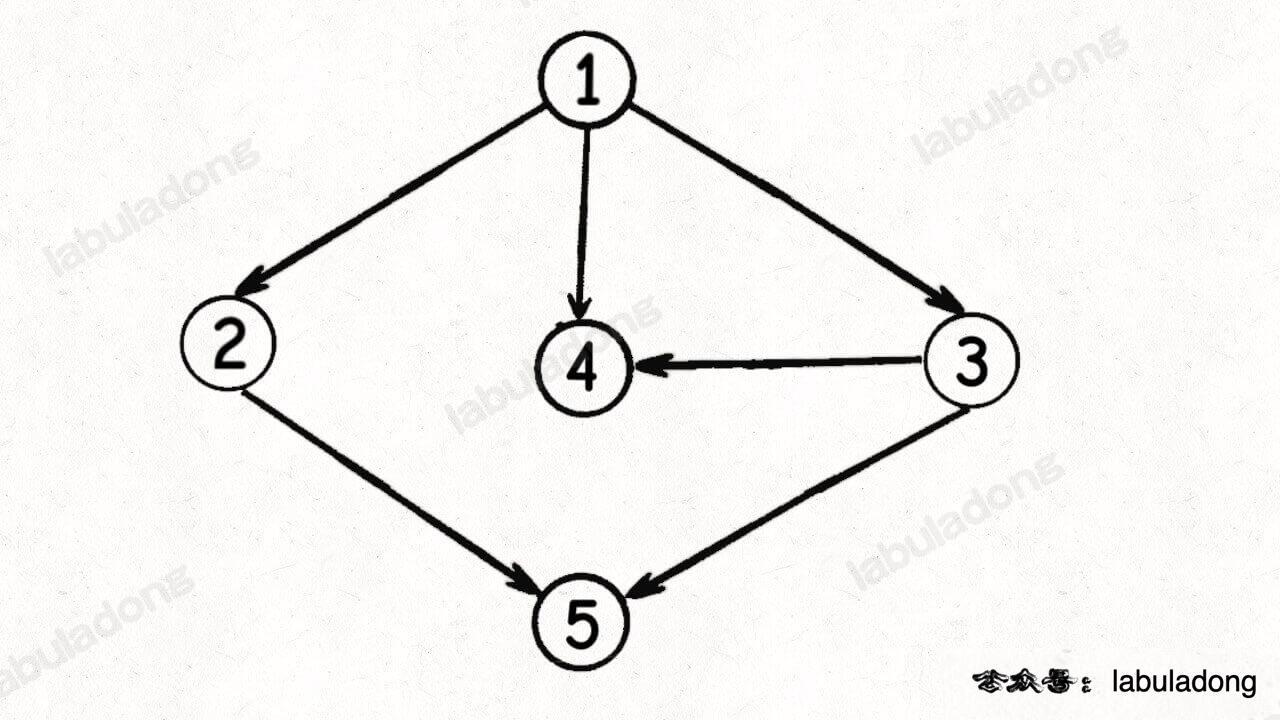
Clearly, this order is a feasible result of a topological sort.
Therefore, by slightly modifying the cycle detection algorithm with BFS to record the order of node traversal, you can obtain the result of a topological sort:
class Solution {
public int[] findOrder(int numCourses, int[][] prerequisites) {
// Build the graph, same as in cycle detection algorithm
List<Integer>[] graph = buildGraph(numCourses, prerequisites);
// Calculate in-degrees, same as in cycle detection algorithm
int[] indegree = new int[numCourses];
for (int[] edge : prerequisites) {
int from = edge[1], to = edge[0];
indegree[to]++;
}
// Initialize the queue with nodes having in-degree
// of 0, same as in cycle detection algorithm
Queue<Integer> q = new LinkedList<>();
for (int i = 0; i < numCourses; i++) {
if (indegree[i] == 0) {
q.offer(i);
}
}
// Record the topological sort result
int[] res = new int[numCourses];
// Record the order of traversed nodes (index)
int count = 0;
// Start executing BFS algorithm
while (!q.isEmpty()) {
int cur = q.poll();
// The order of nodes being dequeued is the topological sort result
res[count] = cur;
count++;
for (int next : graph[cur]) {
indegree[next]--;
if (indegree[next] == 0) {
q.offer(next);
}
}
}
if (count != numCourses) {
// A cycle exists, topological sort is not possible
return new int[]{};
}
return res;
}
// Function to build the graph
List<Integer>[] buildGraph(int n, int[][] edges) {
// See above
}
}class Solution {
public:
vector<int> findOrder(int numCourses, vector<vector<int>>& prerequisites) {
// build the graph, same as the cycle detection algorithm
vector<vector<int>> graph = buildGraph(numCourses, prerequisites);
// calculate the in-degree, same as the cycle detection algorithm
vector<int> indegree(numCourses);
for (vector<int> edge : prerequisites) {
int from = edge[1], to = edge[0];
indegree[to]++;
}
// initialize the queue with nodes having zero
// in-degree, same as the cycle detection algorithm
queue<int> q;
for (int i = 0; i < numCourses; i++) {
if (indegree[i] == 0) {
q.push(i);
}
}
// record the topological sort result
vector<int> res(numCourses);
// record the order of traversed nodes (index)
int count = 0;
// start executing the BFS algorithm
while (!q.empty()) {
int cur = q.front();
q.pop();
// the order of popped nodes is the topological sort result
res[count] = cur;
count++;
for (int next : graph[cur]) {
indegree[next]--;
if (indegree[next] == 0) {
q.push(next);
}
}
}
if (count != numCourses) {
// a cycle exists, topological sort is not possible
return {};
}
return res;
}
private:
vector<vector<int>> buildGraph(int n, vector<vector<int>>& edges) {
// see previous text
}
};class Solution:
def findOrder(self, numCourses: int, prerequisites: List[List[int]]) -> List[int]:
# build the graph, same as in the cycle detection algorithm
graph = self.buildGraph(numCourses, prerequisites)
# calculate in-degrees, same as in the cycle detection algorithm
indegree = [0] * numCourses
for edge in prerequisites:
from_arc, to = edge[1], edge[0]
indegree[to] += 1
# initialize the queue with nodes of in-degree 0,
# same as in the cycle detection algorithm
q = collections.deque()
for i in range(numCourses):
if indegree[i] == 0:
q.append(i)
# record the topological sorting result
res = [0] * numCourses
# record the order of traversed nodes (index)
count = 0
# start executing the BFS algorithm
while q:
cur = q.popleft()
# the order of nodes popped is the topological sorting result
res[count] = cur
count += 1
for next_arc in graph[cur]:
indegree[next_arc] -= 1
if indegree[next_arc] == 0:
q.append(next_arc)
if count != numCourses:
# a cycle exists, topological sorting is not possible
return []
return res
def buildGraph(self, n: int, edges: List[List[int]]) -> List[List[int]]:
# see previous text
passfunc findOrder(numCourses int, prerequisites [][]int) []int {
// build the graph, same as the cycle detection algorithm
graph := buildGraph(numCourses, prerequisites)
// calculate indegree, same as the cycle detection algorithm
indegree := make([]int, numCourses)
for _, edge := range prerequisites {
to := edge[0]
indegree[to]++
}
// initialize the queue with nodes having zero
// indegree, same as the cycle detection algorithm
q := make([]int, 0)
for i := 0; i < numCourses; i++ {
if indegree[i] == 0 {
q = append(q, i)
}
}
// record the topological sort result
res := make([]int, numCourses)
// record the order of traversed nodes (index)
count := 0
// start executing the BFS algorithm
for len(q) > 0 {
cur := q[0]
q = q[1:]
// the order of popped nodes is the topological sort result
res[count] = cur
count++
for _, next := range graph[cur] {
indegree[next]--
if indegree[next] == 0 {
q = append(q, next)
}
}
}
if count != numCourses {
// there exists a cycle, topological sort is not possible
return []int{}
}
return res
}
func buildGraph(n int, edges [][]int) [][]int {
// see previous text
}var findOrder = function(numCourses, prerequisites) {
// build the graph, same as in cycle detection algorithm
let graph = buildGraph(numCourses, prerequisites);
// calculate in-degrees, same as in cycle detection algorithm
let indegree = new Array(numCourses).fill(0);
for (let edge of prerequisites) {
let from = edge[1], to = edge[0];
indegree[to]++;
}
// initialize the queue with nodes having zero
// in-degree, same as in cycle detection algorithm
let q = [];
for (let i = 0; i < numCourses; i++) {
if (indegree[i] == 0) {
q.push(i);
}
}
// record the topological sorting result
let res = new Array(numCourses).fill(0);
// record the order of traversal (index)
let count = 0;
// start executing the BFS algorithm
while (q.length !== 0) {
let cur = q.shift();
// the order of popped nodes is the topological sorting result
res[count] = cur;
count++;
for (let next of graph[cur]) {
indegree[next]--;
if (indegree[next] == 0) {
q.push(next);
}
}
}
if (count != numCourses) {
// there is a cycle, so topological sorting does not exist
return [];
}
return res;
};
// function to build the graph
var buildGraph = function(n, edges) {
// see previous text
};Generally, graph traversal algorithms require a visited array to prevent revisiting nodes. In this BFS algorithm, the indegree array serves the function of the visited array. Only nodes with an indegree of 0 can be enqueued, ensuring there are no infinite loops.
Alright, we've covered the BFS implementations for cycle detection and topological sorting. Here's a thought-provoking question for you:
For the BFS-based cycle detection algorithm, if you were asked to identify the specific nodes that form a cycle, how would you implement it?