Implement HashMap with Separate Chaining
Prerequisite Knowledge
Before reading this article, you should first learn:
In the previous article Core Principles of Hash Tables, I introduced the core principles and key concepts of hash tables. It mentioned that there are two main methods to resolve hash collisions: the chaining method and open addressing method (also known as linear probing):
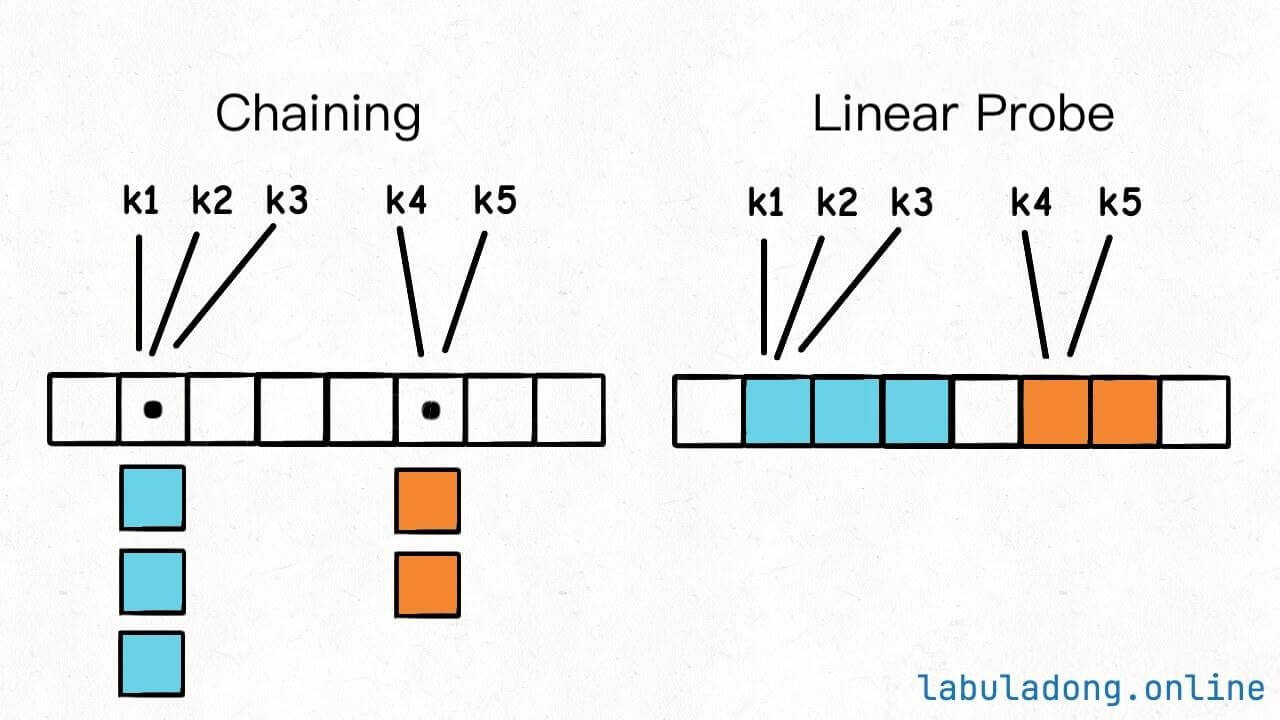
This article will specifically introduce the implementation principles and code for the chaining method.
Firstly, I will use a visualization panel to implement a simplified version of a hash table using the chaining method. This will help you intuitively understand how the chaining method implements the APIs for adding, deleting, finding, and updating, and how it resolves hash collisions. Finally, I will provide a more complete Java code implementation.
Simplified Implementation of the Chaining Method
The article Core Principles of Hash Tables has already explained the relationship between hash functions and the type of key. The role of a hash function is to convert a key into an index of an array in time, and a key can be of any immutable type.
However, to facilitate understanding here, I will make the following simplifications:
The hash table we implement only supports
keyandvaluetypes asint. If thekeydoes not exist, it returns-1.The
hashfunction we implement is simply a modulo operation, i.e.,hash(key) = key % table.length. This also conveniently simulates hash collisions, for example, whentable.length = 10, bothhash(1)andhash(11)produce the value 1.The size of the underlying
tablearray is fixed upon the creation of the hash table, without considering load factors or dynamic resizing.
These simplifications help us focus on the core logic of adding, deleting, finding, and updating, and can be supported by the visualization panel to enhance understanding.